普通字符
[ABC]
匹配 “ [ ] “ 内所有字符
[^ABC]
匹配除 “ [ ] “ 内所有字符
[A-Z]
区间匹配,字母A-Z
.
除了换行符外的任何单个字符
[\s\S]
# 注意反斜杠
小写s代指空白符(换行符一类),大写S代表非空白符
\ w \d
前者等价于 [A-Za-z0-9_],即所有字母数字下划线;后者指代所有数字
特殊字符
$
匹配到整个字符串的结尾位置。若设置 RegExp 对象的 Multiline 属性则可以多行匹配
( )
标记一个子表达式的开始和结束位置
*
匹配前面的子表达式零次或多次【无或有或更多】
+
匹配前面的子表达式一次或多次【有或更多】
?
匹配前面的子表达式零次或一次【无或有】
|
指明两项之间的一个选择
捕获
我也不知道这个标题应该咋起,主要是爬虫的时候会用到,简单易懂地写一写吧
?= 和 ?<=
?! 和 ?<!
和上面相反,感叹号代表否定(像是Python和C中的不等号是!=),放在主体前则要加 “<” 后面则不用。
作用
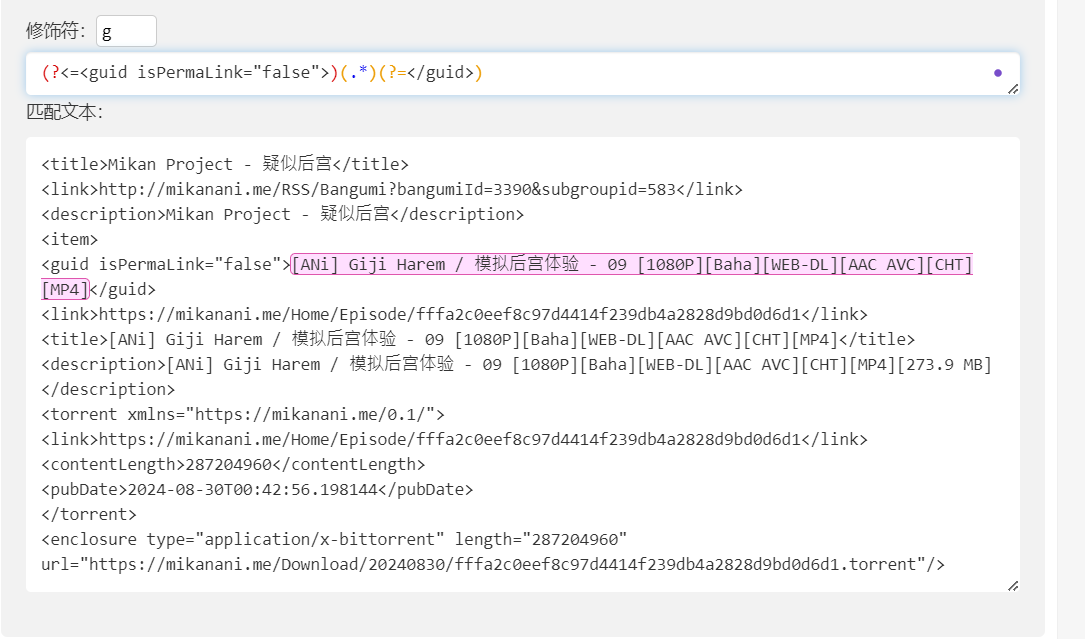
这篇文章是在计划抓取RSS feed内容的时候写的,故而根据上述所学,几乎可以简单抓取必要信息(以Mikan Project提供的feed为例),标题和磁链都可以直接获取(不直接下载种子是因为Aria2可以直接输入磁链批量下载,而用种子的话好像只能单个QuQ)
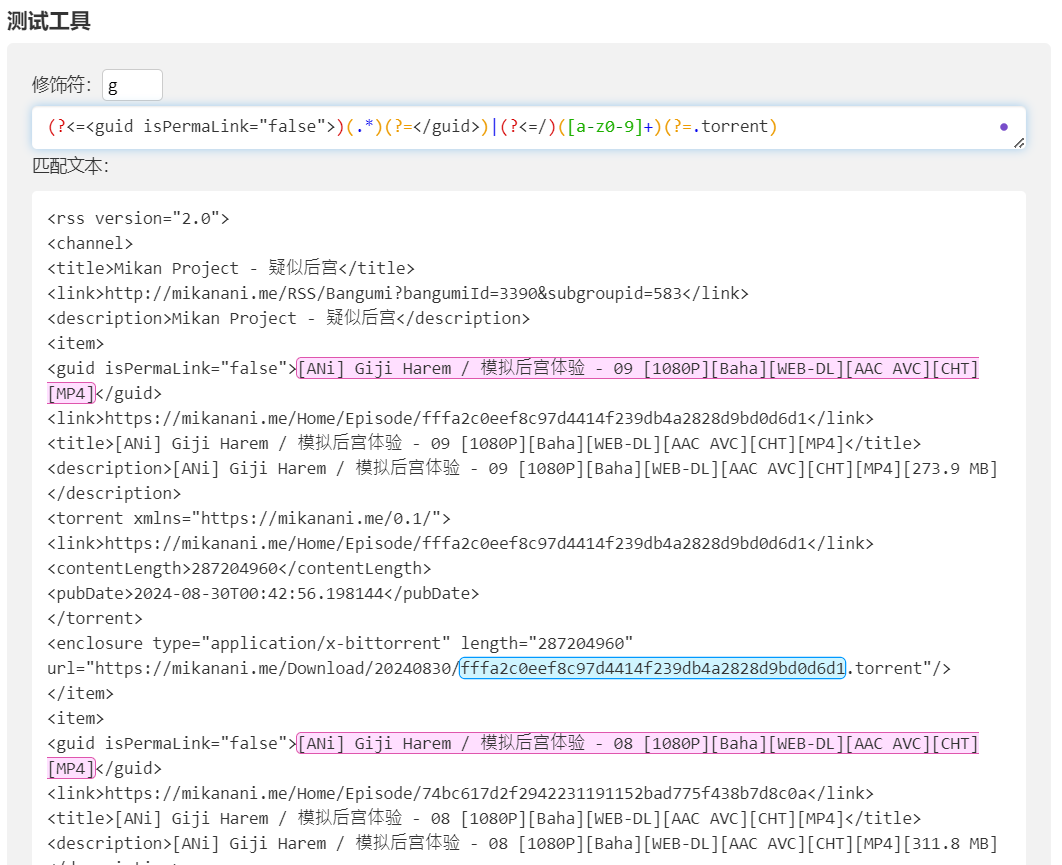
项目开始后的补充:
用findall的时候,要改为(.*?)非贪婪模式,否则容易过度抓取
参考来源:菜鸟教程