你的内容
1. 生成6位数字随机验证码 1 2 3 4 5 6 7 8 9 10 11 12 import randomimport stringdef num_code (length=6 ): """ 生成长度为length的数字随机验证码 :param length: 验证码长度 :return: 验证码 """ return '' .join(random.choice(string.digits) for i in range (0 , length))
2.md5加密 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import hashlibdef md5_encrypt (en_str ): """ 使用md5二次加密生成32位的字符串 :param en_str: 需要加密的字符串 :return: 加密后的字符串 """ md5 = hashlib.md5() md5.update(en_str.encode('utf-8' )) md5.update(md5.hexdigest().encode('utf-8' )) return md5.hexdigest()
3. 生成唯一token import uuid
import hashlib
def only_token():
"""
使用md5加密uuid生成唯一的32位token
:return: 加密后的字符串
"""
md5 = hashlib.md5() # 使用MD5加密模式
md5.update(str(uuid.uuid1()).encode('utf-8'))
return md5.hexdigest()
4、发送手机验证码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #验证码管理表 class AuthCode(models.Model): name = models.CharField(max_length=10,default=None, null=True, blank=True,verbose_name='姓名') phone = models.CharField(max_length=11, unique=True, verbose_name='手机号') code = models.CharField(max_length=6,verbose_name='验证码') purpose = models.IntegerField(default=0,verbose_name='用途:0->注册验证 1->找回密码 2->其它') sendNum = models.IntegerField(default=0,verbose_name='发送次数') isCanGet = models.BooleanField(default=0,verbose_name='0->可以获取,1->不可以获取') recentlySendTime = models.DateTimeField(auto_now_add=True,verbose_name='最近一次发送时间') creation_time = models.DateTimeField(auto_now=True, verbose_name='创建时间') class Meta: verbose_name = '手机验证码' verbose_name_plural = verbose_name
实现逻辑 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import http.client import urllib # 使用互亿无线 host = "106.ihuyi.com" sms_send_uri = "/webservice/sms.php?method=Submit" # 查看用户名 登录用户中心->验证码通知短信>产品总览->API接口信息->APIID account = "你的用户名" # 查看密码 登录用户中心->验证码通知短信>产品总览->API接口信息->APIKEY password = "你的密码" def send_sms(text, mobile): text = f"您的验证码是:{text}。请不要把验证码泄露给其他人。" params = urllib.parse.urlencode( {'account': account, 'password': password, 'content': text, 'mobile': mobile, 'format': 'json'}) headers = {"Content-type": "application/x-www-form-urlencoded", "Accept": "text/plain"} conn = http.client.HTTPConnection(host, port=80, timeout=30) conn.request("POST", sms_send_uri, params, headers) response = conn.getresponse() response_str = response.read() conn.close() return response_str if __name__ == '__main__': mobile = "手机号" text = '123122' print(json.loads(send_sms(text, mobile).decode('utf-8')))
5、生成二维码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import qrcode import io def maker_qrcode(url): """ 生成二维码 :param url: 需要生成二维码的url :return: 返回图片字节流 """ image = qrcode.make(url) # 创建二维码片 buffer = io.BytesIO() # 将图片内容丢入容器 image.save(buffer, 'png') # 返回容器内的字节 return buffer.getvalue() 或者 from .settings import BASE_DIR def create_qrcode(name, url): """ 生成机器扫码支付二维码 :param name: 图片名称 :param url: 支付路由 :return: """ img = qrcode.make(url, border=0) # 创建二维码片 save_path = BASE_DIR + '/' + name + '.png' print(save_path) img.save(save_path) return img
6.微信群发 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 # coding=utf8 import itchat, time itchat.auto_login(True) SINCERE_WISH = u'祝%s新年快乐!' friendList = itchat.get_friends(update=True)[35:] count = 0 for index,friend in enumerate(friendList): print(index,friend['DisplayName'],friend['NickName']) itchat.send(SINCERE_WISH % (friend['DisplayName'] or friend['NickName']), friend['UserName']) time.sleep(2) print('备注名称',friend['DisplayName'],'昵称',friend['NickName'],'用户名',friend['UserName']) print("----end----") """ # 发送文本 itchat.send('Hello, WeChat!') # 发送图片 itchat.send_image('my_picture.png') # 发送视频 itchat.send_video('my_video.mov') # 发送文件 itchat.send_file('my_file.zip') """
7、微信自动回复 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 # -*- coding=utf-8 -*- import requests import itchat import random #图灵机器人 #http://www.tuling123.com/member/robot/1380138/center/frame.jhtml?page=0&child=0获取apikey KEY = '你的KEY' def get_response(msg): apiUrl = 'http://www.tuling123.com/openapi/api' data = { 'key' : KEY, 'info' : msg, 'userid' : 'wechat-robot', } try: r = requests.post(apiUrl, data=data).json() return r.get('text') except: return @itchat.msg_register(itchat.content.TEXT) def tuling_reply(msg): defaultReply = 'I received: ' + msg['Text'] robots=['','',''] reply = get_response(msg['Text'])+random.choice(robots) return reply or defaultReply itchat.auto_login(enableCmdQR=False) itchat.run()
8、提取Django中model中的字段名变成字典、列表 1 2 3 4 5 6 7 8 9 10 11 12 import re t = """ goods_id = models.IntegerField(verbose_name='商品编号') label_code = models.CharField(max_length=20, verbose_name='商品标签') """ # 字典 print({k:None for k in re.findall('([a-z_A-Z]+)\s=\s',t)}) # 列表 # print([k for k in re.findall('([a-z_A-Z]+)\s=\s',t)]) 输出 {'goods_id': None, 'lable_code': None}
9、数据库中给表创建数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import pymysql def createData(dataDict,tableName): """ 给数据表创建数据 :param dataDict: 字典 :param tableName: 表名 :return: """ #连接数据库 conn = pymysql.connect( host='192.168.0.188', #数据库所在地址URL user='root', #用户名 password='123456', #密码 database='名称', #数据库名称 port=3306, #端口号 charset='utf8' ) #拿到查询游标 cursor = conn.cursor() clos,value = zip(*dataDict.items()) sql = "INSERT INTO `%s`(%s) VALUES (%s)" % (tableName, ','.join(clos), ','.join(['%s'] * len(value)) ) print(sql) cursor.execute(sql, value) conn.commit() cursor.close() conn.close() print('Done')
10.捕捉异常 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 try: pass except 异常类型 as e: pass finally: pass 异常类型 Exception 全部异常 AttributeError 试图访问一个对象没有的属性,比如foo.x,但是foo没有属性x IOError 输入/输出异常;基本上是无法打开文件 ImportError 无法引入模块或包;基本上是路径问题或名称错误 IndentationError 语法错误(的子类) ;代码没有正确对齐 IndexError 下标索引超出序列边界,比如当x只有三个元素,却试图访问x[5] KeyError 试图访问字典里不存在的键 KeyboardInterrupt Ctrl+C被按下 NameError 使用一个还未被赋予对象的变量 SyntaxError Python代码非法,代码不能编译(个人认为这是语法错误,写错了) TypeError 传入对象类型与要求的不符合 UnboundLocalError 试图访问一个还未被设置的局部变量,基本上是由于另有一个同名的全局变量,导致你以为正在访问它 ValueError 传入一个调用者不期望的值,即使值的类型是正确的
11、获取当前时间 1 2 3 4 5 6 7 8 9 import datetime current_time = str(datetime.datetime.now())[:19] print(current_time) 输出格式如:2018-10-20 10:01:43 local_time = time.strftime('%Y%m%d%H%M%S', time.localtime(time.time())) print(local_time)
12、订单编号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from random import Random import time def random_str(randomlength=8): str = '' chars = 'AaBbCcDdEeFfGgHhIiJjKkLlMmNnOoPpQqRrSsTtUuVvWwXxYyZz0123456789' length = len(chars) - 1 random = Random() for i in range(randomlength): str+=chars[random.randint(0, length)] return str def order_num(): """ 生成付款订单号 :return: """ local_time = time.strftime('%Y%m%d%H%M%S', time.localtime(time.time())) result = local_time + random_str(5) return result print(order_num())
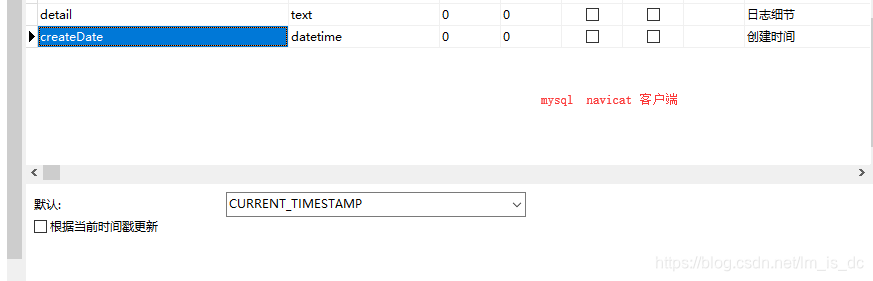
13、mysql自动填写当前时间
1 2 3 4 为表添加索引 ALTER table tableName ADD INDEX indexName(columnName)
14、drf动态过滤查询 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 # page.py from rest_framework.pagination import PageNumberPagination class UserPagination(PageNumberPagination): """用户分页器""" page_size = 10 # 默认的页面数据数量 page_query_param = 'page' # 定制取数据页码key page_size_query_param = 'page_size' # 默认取数据页码key max_page_size = 15 # 数据每页取值的最大上限 # serializers.py from rest_framework import serializers from user.models import UserInfo class UserSerializers(serializers.ModelSerializer): """用户收货地址""" class Meta: model = UserInfo # 所有字段 #fields = '__all__' fields = ['name', 'code', 'title', 'province', 'city', 'quxian', 'address', 'code__gte', 'code__lte'] # 显示外键 depth = 2 # views.py class MachineViews(APIView): def get(self, request, *args, **kwargs): # 从前端获取出来的过滤参数,解析成字典传进filter()函数中 # 动态过滤, kwargs = {} # 表中的字段名 columns = ['name', 'code', 'title', 'province', 'city', 'quxian', 'address', 'code__gte', 'code__lte'] for k, v in request.query_params.items(): if k not in columns: return Response('参数不对', status=status.HTTP_400_BAD_REQUEST) if v: kwargs[k] = v users = UserInfo.objects.filter(**kwargs) page = UserPagination() page_goods_list = page.paginate_queryset(users, self.request, self) ser = UserSerializers(page_goods_list, many=True) return page.get_paginated_response(ser.data)
15、linux后台运行python程序 1 2 nohup /home/project_venv/user/bin/python3 -u /home/user/user_server.py >> /home/user/user.log 2>&1 &
16、追加外键 1 2 3 ALTER TABLE tb_commentPhoto ADD CONSTRAINT FK_comment_phone FOREIGN KEY tb_goodsComment(id) REFERENCES tb_commentPhoto(comment_id);
17、写/读CSV文件,查看是否存在,若存在就从csv中删除 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 import csv import random import string def create_invite_code(random_code_pool=None, length=6, num=10, is_append=False): """ 创建随机邀请码,并写入txt文件 :param: random_code_pool 随机邀请码 :param: length 邀请码长度 :param: num 邀请码个数 :param: is_append True追加,False 覆盖 :return: """ if not random_code_pool: code_pool = string.ascii_uppercase + string.digits random_code_pool = [] for i in range(num): s = '' for _ in range(length): s += random.choice(code_pool) if s and s not in random_code_pool: random_code_pool.append(s) # 写入方法。是追加还是覆盖 write_method = 'a+' if is_append else 'w' # 写入文件 with open('./invite_code.csv', write_method, newline='') as f: writer = csv.writer(f) for rowData in random_code_pool: # 按行写入 writer.writerow((rowData,)) def check_invite_code(code): """ 查看邀请码是否存在txt文件中, 若存在就返回True,并在txt文件中删除 若不存在就返回False :param code: :return: """ code_pool = [] with open('./invite_code.csv', 'r', encoding='utf-8',errors='ignore') as f: allFileInfo = csv.reader(f) for row in allFileInfo: code_pool.append(row[0]) if code in code_pool: # 删除查询的code code_pool.pop(code_pool.index(code)) # 重新写入文件 create_invite_code(code_pool,is_append=False) return True return False if __name__ == '__main__': # create_invite_code(length=9,num=100) print(check_invite_code('WJ4PSTJG2'))
18、django中从request获取访问路径 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 print('获取相对路径', request.get_full_path()) print('获取绝对路径', request.build_absolute_uri()) print(request.build_absolute_uri('?')) print(request.build_absolute_uri('/')[:-1].strip("/")) print(request.build_absolute_uri('/').strip("/")) print(request.build_absolute_uri('/')) print('----------') print(request.META['HTTP_HOST']) print(request.META['PATH_INFO']) print(request.META['QUERY_STRING']) iphost = request.META.get('REMOTE_ADDR', '') # 获取访问来源IP # 输出如: 获取相对路径 /QRcode/?d=1 获取绝对路径 http://127.0.0.1:8000/QRcode/?d=1 http://127.0.0.1:8000/QRcode/ http://127.0.0.1:8000 http://127.0.0.1:8000 http://127.0.0.1:8000/ ---------- 127.0.0.1:8000 /QRcode/ d=1
19、Django收集静态文件 1 2 3 4 5 先在项目根目录下创建一个static文件夹 然后在settings.py中设置 STATIC_ROOT = os.path.join(BASE_DIR, 'static') 最后执行下面的命令: python manage.py collectstatic
20、xadmin插件 https://www.cnblogs.com/lanqie/p/8340215.html
21、uwsgi自动重启 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 [uwsgi] # 使用nginx连接时 使用 socket=0.0.0.0:2019 # 直接作为web服务器使用 #http=0.0.0.1:8000 # 配置工程目录 chdir=/home/user # 配置项目的wsgi目录。相对于工程目录 wsgi-file=user/wsgi.py virtualenv=/home/project_venv/user #配置进程,线程信息 processes=1 threads=1 enable-threads=True master=True pidfile=uwsgi.pid daemonize=uwsgi.log #启动uwsgi的用户名和用户组 uid=root gid=root #uwsgi自动重启 py-autoreload=1
22、谷歌浏览器快捷键 1 2 3 4 5 6 浏览器缓存 Ctrl+Shift+Del 清除Google浏览器缓存的快捷键 Ctrl+Shift+R 重新加载当前网页而不使用缓存内容
23、git克隆分支 24、mysql更新语句、新增列、删除列 1 2 3 4 5 6 7 8 update user set name='张三' where id=111 # 删除 DELETE FROM table_name [WHERE Clause] # 增加字段 alter table 表名 add column 列名 类型; # 删除字段 alter table 表名 dropcolumn 列名 ;
25、删除指定格式的文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import os import re def remove_specified_format_file(file_dir, format_name): """ 删除指定格式的文件 :param file_dir: 文件根目录 :param format_name: 格式 :return: """ for root, dirs, files in os.walk(file_dir): # print(root) #当前目录路径 # print(dirs) #当前路径下所有子目录 # print(files) #当前路径下所有非目录子文件 for file in files: if re.match(format_name, file): print(os.path.join(root, file)) os.remove(os.path.join(root, file)) remove_specified_format_file(r'D:\学习\LDC\java', r'\._*')
26、计算文件总数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import os def file_count(file_dir): """ :param file_dir: 文件根目录 :return: """ count = 0 for root, dirs, files in os.walk(file_dir): # print(root) #当前目录路径 # print(dirs) #当前路径下所有子目录 # print(files) #当前路径下所有非目录子文件 count += len(files) return count print(file_count(r'D:\学习\LDC\java\Java学习\newEstore\estore\js'))
27、计算文件夹大小 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import os def file_size(file_dir): """ 删除指定格式的文件 :param file_dir: 文件根目录 :return: """ size = 0 for root, dirs, files in os.walk(file_dir): # print(root) #当前目录路径 # print(dirs) #当前路径下所有子目录 # print(files) #当前路径下所有非目录子文件 for file in files: size += os.path.getsize(os.path.join(root, file)) # M为单位 return size / 1024 / 1024 file_name = r'D:\学习' print(file_size(file_name))
28、Django实现jsonp跨域 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 # html $.ajax({ url: '请求路由', type: 'GET', dataType: 'JSONP', data:{ code: 'yes', }, jsonp: 'callback', success: function(res) { var selectData = $.parseJSON(res); alert(selectData); }, error: function(err) { } }) # views.py def get(self, request, *args, **kwargs): code = request.GET.get('code', '') # 跨域请求 callback = request.GET.get('callback', '') return HttpResponse("%s('%s')" % (callback, json.dumps({'code': code})), status=status.HTTP_200_OK) cors解决跨域 https://www.cnblogs.com/wxiaoyu/p/9578848.html
29、微信获取用户信息 参考:https://blog.csdn.net/weixin_39735923/article/details/79202563
30、uwsgi初始配置问题 https://blog.csdn.net/weixin_39735923/article/details/79202563
31、django中drf序列化 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 # 序列化器 class MsgSerializers(serializers.ModelSerializer): addtime = serializers.DateTimeField(read_only=True, format="%Y-%m-%d %H:%M:%S") hasread = serializers.CharField(source='get_hasread_display') msgtype = serializers.CharField(source='get_msgtype_display') class Meta: model = MallMsg # 可以混合使用 fields = '__all__' # '__all__' 所有字段 # 数据库层级控制(序列化链表操作) # depth = 1 # 外键层级 #分页器 from rest_framework.pagination import PageNumberPagination class MyLimitOffsetPagination(PageNumberPagination): page_size = 3 # 默认的页面数据数量 page_query_param = 'page' # 定制取数据页码key ? page_size_query_param = 'page_size' # 默认取数据页码key & max_page_size = 15 # 数据每页取值的最大上限
32、第三方库 1 2 安装openssl pip3 install pyOpenSSL
33、requests请求https携带CA证书 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 import OpenSSL import requests import urllib3.contrib.pyopenssl urllib3.contrib.pyopenssl.inject_into_urllib3() def p12_to_pem(certname, pwd): """ 从.p12文件中提取pem :param certname: :param pwd: :return: """ pem_name = certname + ".pem" f_pem = open(pem_name, 'wb') p12file = certname + ".p12" p12 = OpenSSL.crypto.load_pkcs12(open(p12file, 'rb').read(), pwd) f_pem.write(OpenSSL.crypto.dump_privatekey(OpenSSL.crypto.FILETYPE_PEM, p12.get_privatekey())) f_pem.write(OpenSSL.crypto.dump_certificate(OpenSSL.crypto.FILETYPE_PEM, p12.get_certificate())) ca = p12.get_ca_certificates() if ca is not None: for cert in ca: f_pem.write(OpenSSL.crypto.dump_certificate(OpenSSL.crypto.FILETYPE_PEM, cert)) f_pem.close() return pem_name def post_cert_request(url, data,header, certname, pwd): """ 使用证书发起https请求 :param url: :param data: :param certname: :param pwd: :return: """ if (certname != ""): cert = p12_to_pem(certname, pwd) else: cert = None r = requests.post(url, header=header, data=data, cert=cert) return r
34、django创建缓存命令 1 python manage.py createcachetable 缓存表名
35、Django 更改超级用户密码 1 2 3 4 5 6 7 8 在工程文件目录下敲入: python manage.py shell 再在python交互界面输入: from django.contrib.auth.models import User user = User.objects.get(username = '用户名') user.set_password('密码') user.save()
36、restframe使用缓存 https://blog.csdn.net/Odyssues_lee/article/details/80872586
37、数据库 1 2 select * from user where ISNULL(code) update user set code='111',info='微信' where ISNULL(code)
38、linux常用命令 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 tail -f 日志名 实时监控日志 tail -f 80_v10.log netstat -na|grep 80 查看端口tcp连接数 netstat -na|grep 80 | wc -l 计算端口tcp连接数 ps -ef|grep python 查看有多少python程序在运行 gunzip 2015.csv.gz # 解压 unzip 19.zip # 解压zip wc -l 2015.csv # 查看行数 apt install lrzsz # 安装 sz 文件名 # 下载文件 查找文件 find / -name 文件名 匹配执行过的以find为开头的命令 history | grep find
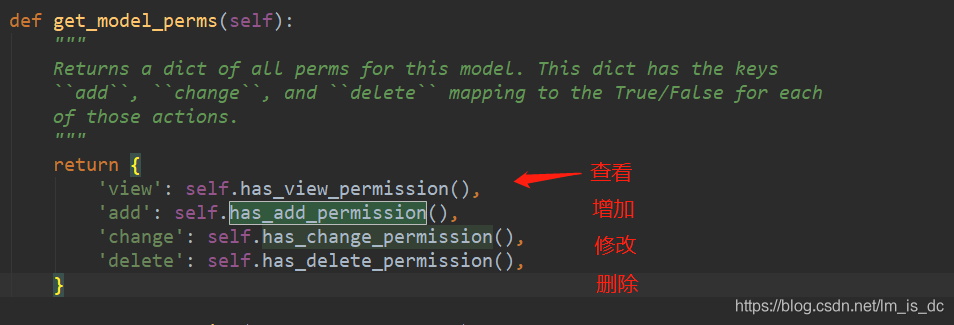
39、xadmin禁止增加、删除 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 # models.py # 用户管理 class UserManage(models.Model): name = models.CharField(max_length=20, verbose_name='用户名') phone = models.CharField(max_length=11, unique=True, verbose_name='手机号') code = models.CharField(max_length=11, unique=True, verbose_name='编号') user = models.ForeignKey(User, on_delete=models.CASCADE, editable=False, null=True, verbose_name='管理员') # adminx.py # 用户列表 class UserAdmin(object): list_display = [ 'code', 'phone', 'name',] search_fields = ['code', 'phone'] list_filter = ['code', 'phone'] list_editable = ['name'] # 数据即时编辑 readonly_fields = ['code', 'phone', 'name'] # 只读字段,不能编辑 model_icon = 'fa fa-square' model = UserInfo def has_delete_permission(self, *args, **kwargs): # 禁止删除 if args: return True return False def has_add_permission(self,*args,**kwargs): # 禁止增加 return False def save_models(self): # 用户级别设置 self.new_obj.user = self.request.user flag = self.org_obj is None and 'create' or 'change' if flag == 'create': # 对密码字段进行加密 self.new_obj.password = encrypt_oracle(self.new_obj.password) elif flag == 'change': if 'password' in self.change_message(): self.new_obj.password = encrypt_oracle(self.new_obj.password) else: pass super().save_models() xadmin.site.register(UserInfo, UserAdmin)
40、时间格式字符串相减 1 2 3 4 5 6 7 8 9 10 11 12 import datetime import time start = str(datetime.datetime.now())[:19] time.sleep(60) end = str(datetime.datetime.now())[:19] print(start,end) link_start = datetime.datetime.strptime(start, '%Y-%m-%d %H:%M:%S') link_end = datetime.datetime.strptime(end, '%Y-%m-%d %H:%M:%S') link_min = round((link_end - link_start).seconds / 60, 2) print(link_min,'分钟')
41、显示循环进度条 参考:https://blog.csdn.net/zejianli/article/details/77915751
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 from tqdm import tqdm,trange from time import sleep text = "" for char in tqdm(["a", "b", "c", "d"]): text = text + char sleep(1) # 方式二 import time def process_bar(percent, index, total,start_time, start_str='', end_str='', total_length=100): # 进度条 percent_length = int(percent) bar = '\r' + start_str + ('\033[1;31;41m \033[0m' * percent_length + '\033[1;37;47m \033[0m' * ( total_length - percent_length)) + f' {round(index / total * 100, 2)}% ' + f' {index}|{end_str}'+ f' |已进行时间: {round(time.time() - start_time, 2)}秒' print(bar, end='', flush=True) if __name__ == '__main__': data_set = [i for i in range(23)] i = 0 start_time = time.time() total = len(data_set) end_str = '{}'.format(total) for data in data_set: time.sleep(1) i += 1 process_bar(i * 100 / total, i, total, start_time, start_str='', end_str=end_str, total_length=100) # 方式三 import sys import time d = [i for i in range(100)] for i in range(len(d)): time.sleep(1) sys.stdout.write('\r>> Downloading %.2f%%' % (float(i) / float(len(d)) * 100.0)) sys.stdout.flush()
42、把列表中的字典转成csv文件 1 2 3 4 5 6 import pandas as pd lists = [{'a':1,'b':2},{'a':2,'b':3}] df = pd.DataFrame(lists) print(df) df.to_csv('result2.csv')
43、windows添加右键新建MarkDown文件 在网上下载Typora软件安装后
1 2 3 4 Windows Registry Editor Version 5.00 [HKEY_CLASSES_ROOT\.md\ShellNew] "NullFile"="" "FileName"="template.md"
2、另存为,改后缀为.reg,保存类型为.txt,编码为Unicode
3、双击运行,确定,重启电脑,此时在桌面右键就有了新建md文件
44、redis设置值定时过期 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import datetime import redis redis_client = redis.Redis( host='127.0.0.1', port=6379, db=0, password='123456' ) def redis_set(): """ redis设置值定时过期 :return: """ global redis_client redis_client.set('name','ldc') now = datetime.datetime.now() # 设置‘name’50秒过期 expire_time = now + datetime.timedelta(hours=0, minutes=0, seconds=50) redis_client.expireat('name', expire_time) if __name__ == '__main__': redis_set()
45、linux根据端口杀进程 1 2 3 4 5 6 7 8 9 10 11 12 import os def killport(port): command = '''kill -9 $(netstat -nlp | grep :''' + str(port) + ''' | awk '{print $7}' | awk -F"/" '{ print $1 }')''' os.system(command) # 开始执行 if __name__ == '__main__': port = 4237 killport(port)
46、监控linux网络流量 1 2 3 4 5 6 7 8 iftop -n -N -i eth0 nethogs eth0 vim +/字符串 文件
47、win10添加右键打开cmd 通过添加注册表项实现
win + r 输入 regedit
找到注册表位置:HKEY_CLASSES_ROOT\Directory\Background\shell\
右键“shel”l,新建“项”,命名为“以管理员身份打开cmd”,
右键“以管理员身份打开cmd”,新建“DWORD(32位)值”,命名为”ShowBasedOnVelocityId”,值为“639bc8”
右键“以管理员身份打开cmd”,新建“项”,命名为“command”
右键“command”,点击“默认”,点击“修改”,填写数值为 cmd.exe /s /k pushd “%V”
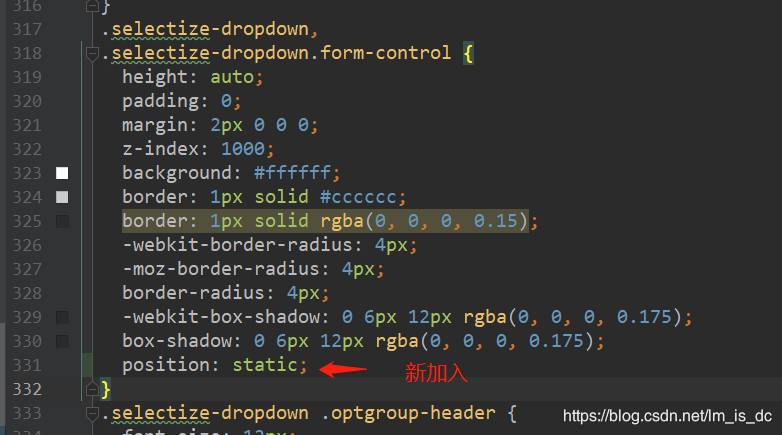
48、xadmin后台无法显示下拉框完整内容 解决方案 在根目录中找到/static/xadmin/vendor/selectize/selectize.bootstrap3.css
49、xadmin单点登录 使用中间件实现。
新建一个utils.py文件,存放以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from django.contrib.sessions.models import Session from django.db.models import Q from django.utils import timezone from django.utils.deprecation import MiddlewareMixin class XadminMiddleware(MiddlewareMixin): def process_request(self, request): """xadmin后台单点登录""" PATH_INFO = request.META.get('PATH_INFO', '') if PATH_INFO and 'xadmin' in PATH_INFO: request.session.clear_expired() # 清除过期的key session_key = request.session.session_key for session in Session.objects.filter(~Q(session_key=session_key), expire_date__gte=timezone.now()): data = session.get_decoded() if data.get('_auth_user_id', None) == str(request.user.id): session.delete()
然后在urls.py中设置:
1 2 3 4 5 urlpatterns = [ ... re_path('^xadmin/', xadmin.site.urls), ... ]
然后在settings.py中注册中间件
1 2 3 4 5 6 7 8 9 MIDDLEWARE = [ ... 'utils.xadminauth.XadminMiddleware', ... ] SESSION_COOKIE_AGE = 1209600 # 设置过期时间 SESSION_SAVE_EVERY_REQUEST = Ture # 每次请求都更新
【参考】 https://blog.csdn.net/Python_anning
50、Django restful 多个models数据表序列化合并返回(一次请求返回多个序列化器数据) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 # 导入第三方包 pip install django-crispy-forms==1.7.2 # 在settings.py中添加应用 INSTALLED_APPS = [ ... 'drf_multiple_model', 'rest_framework', ... ] # 在views.py中使用 from drf_multiple_model.pagination import MultipleModelLimitOffsetPagination from drf_multiple_model.views import ObjectMultipleModelAPIView class LimitPagination(MultipleModelLimitOffsetPagination): # 多个models数据表联合查询,分页,每页限制数据10条 default_limit = 10 class StudentSerializers(serializers.ModelSerializer): """学生表序列化器""" # merchant = MerchantSerializers() register_time = serializers.DateTimeField(read_only=True, format="%Y-%m-%d %H:%M:%S") class Meta: model = Student fields = '__all__' class ClassesSerializers(serializers.ModelSerializer): """班级表序列化器""" # merchant = MerchantSerializers() add_time = serializers.DateTimeField(read_only=True, format="%Y-%m-%d %H:%M:%S") class Meta: model = Classes fields = '__all__' class SchoolSerializers(serializers.ModelSerializer): """学校表序列化器""" # merchant = MerchantSerializers() add_time = serializers.DateTimeField(read_only=True, format="%Y-%m-%d %H:%M:%S") class Meta: model = School fields = '__all__' class StudentInfo(ObjectMultipleModelAPIView): # 获取学生信息,班级信息,学校信息 def get(self, request, *args, **kwargs): uid = request.GET.get('uid', '') # 学生id cid = request.GET.get('cid', '') # 班级id sid = request.GET.get('sid', '') # 学校id self.querylist = [ {'queryset': Student.objects.filter(id=uid).order_by('-id'), 'serializer_class': StudentSerializers, 'label': 'student', }, {'queryset': Classes.objects.filter(id=cid).order_by('-id'), 'serializer_class': ClassesSerializers, 'label': 'classes', }, {'queryset': School.objects.filter(id=sid).order_by('-id'), 'serializer_class': SchoolSerializers, 'label': 'school', }, ] return self.list(request, *args, **kwargs) pagination_class = LimitPagination
51、 Django序列化器返回外键关联数据 通过 related_name=’goods_price’把两个表关联起来,当返回Goods的信息时也会返回相应的GoodsPrice信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 class GoodsPriceSerializers(serializers.ModelSerializer): """商品价格表序列化器""" class Meta: model = GoodsPrice fields = ['price'] class GoodsSerializers(serializers.ModelSerializer): """商品表序列化器""" goods_price = GoodsPriceSerializers(many=True, read_only=True) class Meta: model = Goods fields = ['title','goods_price'] depth = 2 class Goods(models.Model): """商品表""" title = models.CharField(max_length=50, verbose_name='商品名称') class Meta: db_table = 'goods' verbose_name = '商品信息表' verbose_name_plural = verbose_name def __str__(self): return self.title class GoodsPrice(models.Model): """商品价格表,通过外键关联商品信息表""" price = models.DecimalField(max_digits=10, decimal_places=2, default=0, verbose_name='售价') goods = models.ForeignKey(to='Goods', related_name='goods_price', on_delete=models.SET_NULL, blank=True, null=True,verbose_name='商品') def __str__(self): return str(self.price) class Meta: managed = True db_table = 'goodsPrice' verbose_name = '商品售价' verbose_name_plural = verbose_name
52、python Django通过User Agent判断请求来源是微信扫一扫或者是支付宝扫一扫 1 2 3 4 5 6 7 8 9 10 class Footest(APIView): def get(self, request, *args, **kwargs): # print(request.META) if 'MicroMessenger' in request.META['HTTP_USER_AGENT']: return Response(data={'msg': '访问来源是微信'}) elif 'AlipayClient' in request.META['HTTP_USER_AGENT']: return Response(data={'msg': '访问来源是支付宝'}) else: return Response(data={'msg': '访问来源是其他'})
User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
浏览器的 UA 字串
标准格式为: 浏览器标识 (操作系统标识; 加密等级标识; 浏览器语言) 渲染引擎标识 版本信息
获取user-Agent 之后,https://blog.csdn.net/fly910905/article/details/82498813?utm_source=blogxgwz4
53、xadmin后台集成’导入‘插件,导入excel文件 效果图:
1、添加
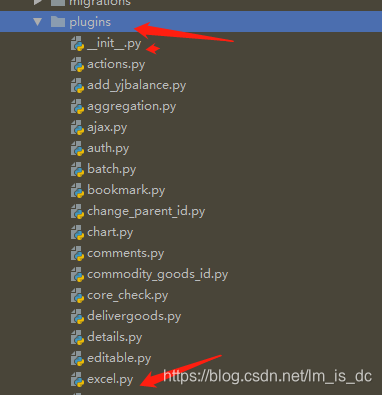
在虚拟环境根目录\Lib\site-packages\xadmin\plugins中添加excel.py文件
from xadmin.views import BaseAdminPlugin, ListAdminView
from django.template import loader
import xadmin
class ListExcelImportPlugin(BaseAdminPlugin):
# 重写init_request
import_excel = False
def init_request(self, *args, **kwargs):
return self.import_excel
def block_top_toolbar(self, context, nodes):
# 这里 xadmin/excel/model_list.top_toolbar.import.html 是自己写的html文件
nodes.append(loader.render_to_string("xadmin/excel/model_list.top_toolbar.import.html"))
xadmin.site.register_plugin(ListExcelImportPlugin, ListAdminView)
在虚拟环境根目录\Lib\site-packages\xadmin\plugins__init__.py中
PLUGINS = (
...
'excel',
...
)
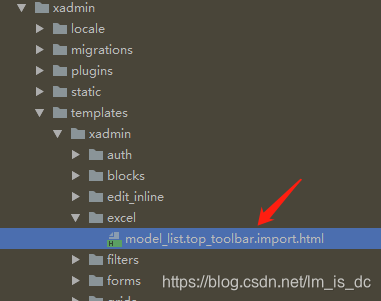
2、添加html文件
在虚拟环境根目录\Lib\site-packages\xadmin\templates\xadmin\中增加文件夹excel,在文件夹中添加model_list.top_toolbar.import.html文件
{% load i18n %}
<div class="btn-group export">
<a class="dropdown-toggle btn btn-default btn-sm" data-toggle="dropdown" href="#">
<i class="icon-share"></i> 导入数据 <span class="caret"></span>
</a>
<ul class="dropdown-menu" role="menu" aria-labelledby="dLabel">
<li><a data-toggle="modal" data-target="#export-modal-import-excel"><i class="icon-circle-arrow-down"></i> 导入
Excel</a></li>
</ul>
<div id="export-modal-import-excel" class="modal fade">
<div class="modal-dialog">
<div class="modal-content">
<form method="post" action="" enctype="multipart/form-data">
<!--{% csrf_token %}-->
<div class="modal-header">
<button type="button" class="close" data-dismiss="modal" aria-hidden="true">×</button>
<h4 class="modal-title">导入 Excel</h4>
</div>
<div class="modal-body">
<input type="file" onchange="fileChange(this)" name="excel" id="submit_upload">
</div>
<div class="modal-footer">
<button type="button" class="btn btn-default" data-dismiss="modal">{% trans "Close" %}</button>
<button class="btn btn-success" type="button" id="submit_upload_b"><i class="icon-share"></i> 导入
</button>
</div>
</form>
</div><!-- /.modal-content -->
</div><!-- /.modal-dalog -->
</div><!-- /.modal -->
</div>
<script type="text/javascript">
function fileChange(target) {
//检测上传文件的类型
var imgName = document.all.submit_upload.value;
var ext, idx;
if (imgName == '') {
document.all.submit_upload_b.disabled = true;
alert("请选择需要上传的 xls 文件!");
return;
} else {
idx = imgName.lastIndexOf(".");
if (idx != -1) {
ext = imgName.substr(idx + 1).toUpperCase();
ext = ext.toLowerCase();
if (ext != 'xls' && ext != 'xlsx') {
document.all.submit_upload_b.disabled = true;
alert("只能上传 .xls 类型的文件!");
return;
}
} else {
document.all.submit_upload_b.disabled = true;
alert("只能上传 .xls 类型的文件!");
return;
}
}
}
$(document).ready(function () {
$('#submit_upload_b').click(function () {
var form_data = new FormData();
var file_info = $('#submit_upload')[0].files[0];
form_data.append('file', file_info);
form_data.append('file_source', $('.breadcrumb li').eq(1).text().trim());
var url = window.location.protocol + '//' + window.location.host + '/importkdorderno/'
$.ajax({
url: url,
type: 'POST',
data: form_data,
dataType: "json",
beforeSend: function (xhr) {
xhr.setRequestHeader("X-CSRFToken", $.getCookie("csrftoken"))
},
processData: false, // tell jquery not to process the data
contentType: false, // tell jquery not to set contentType
success: function (res) {
alert(res.msg);
window.location.reload();
},
error: function (err) {
}
});
});
})
</script>
3、在views.py处理上传的excel文件
import pandas as pd
from rest_framework.views import APIView
class ImportKDOrderNo(APIView):
def post(self, request, *args, **kwargs):
file = request.FILES.get('file')
# read = InMemoryUploadedFile().open()
data = pd.read_excel(file) # 使用pandas处理excel文件
file_source = request.POST.get('file_source', '') # 文件来源
if '订单号' and '物流单号' not in data:
return Response(data={'msg': '文件格式有误,第一行第一列应该为【订单号】,第一行第二列应该为【物流单号】'})
ordernos = data['订单号']
logistics = data['物流单号']
for i in range(len(ordernos)):
print('订单号', ordernos[i], '物流单号', logistics[i])
return Response(data={'msg': '上传成功'})
4、在urls.py中添加访问路由
1 2 3 4 5 6 7 8 9 10 11 12 from django.urls import path from 你的应用名称 import views app_name = '你的应用名称' urlpatterns = [ # 其他路由 ... # 导入物流单号 path('importkdorderno/', views.ImportKDOrderNo.as_view(), name='importkdorderno'), ]
54、Django中查找今天进账金额 views.py
from datetime import datetime
class CountFee(APIView):
def get(self, request, *args, **kwargs):
# 获取当前时间的年月日,然后使用聚合函数添加fee字段的值
year = datetime.now().year
month = datetime.now().month
day = datetime.now().day
count_fees = FeeDetail.objects.filter(addtime__year=year, addtime__month=month, addtime__day=day).aggregate(Sum('fee'))
all_fee = count_fees['fee__sum'] if count_fees['fee__sum'] else 0
print(all_fee)
return Response({'code': 1, 'msg': 'success', 'data': {'all_fee': all_fee}})
55、判断是什么系统 1 2 3 4 5 6 import platform PlATFORM = platform.system() if PlATFORM == "Linux": print('linux') else: print('其他')
56、sql查询 1 2 3 4 # 联合更新 update malluser set master_master_id=3 where master_id in (select a.id from (select id from malluser where id like '15%')a) # 统计某字段重复数据 SELECT phone, COUNT(*) AS sumCount FROM malluser GROUP BY phone HAVING sumCount > 1;
57、 xadmin后台删除数据出现错误 1 `get_deleted_objects() takes 3 positional arguments but 5 were given`
这是由于Django2.1版本和xadmin不兼容导致的
知道虚拟环境\Lib\site-packages\xadmin\plugins\actions.py
修改93行,
把
deletable_objects, model_count, perms_needed, protected = get_deleted_objects(
queryset, self.opts, self.user, self.admin_site, using)
改为
deletable_objects, model_count, perms_needed, protected = get_deleted_objects(
queryset, self.user, self.admin_site)
然后在adminx.py文件中对应的模型类中允许删除
class MaterialAdmin(object):
"""素材库分类"""
list_display = ['id', 'name', 'class_id', 'is_delete', 'addtime']
def has_delete_permission(self, *args, **kwargs):
return True
58、xdamin限制用户点击 1 2 3 4 5 6 7 8 //如果登录z=xadmin后台的账号不是【root】的就不能点击更新操作 var master_name = $('#top-nav').find('strong').text(); master_name = master_name.substring(4); if(master_name != 'root'){ $(".grid-item a").each(function(index, element) { $(this).attr('href','#'); }); }
59、获取公众号关注url 在微信网页版,打开公众号,点击右上角“…”,在弹框中选择右下角中间的“查看历史记录”,然后在弹框中选择左上角倒数第一个,“用默认浏览器打开”,就可以在打开的浏览器中获取该公众号的关注url,当把这个url发给好友时,好友点开的就是去关注公众号的页面。
60、xadmin后台用户操作表权限 虚拟环境根目录\Lib\site-packages\xadmin\views\base.py
可以找到:
在项目子应用下的adminx.py中使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 import xadmin from machine.models import Machine class MachineAdmin(object): list_display = ['code',] # 显示的字段 search_fields = ['code'] # 搜索的字段 list_filter = ['code', 'is_delete'] # 过滤的字段 ordering = ('-id',) # 按id降序排序 list_editable = ['is_delete', ] # 数据即时编辑 list_per_page = 30 # 每页显示数据数量 model_icon = 'fa fa-cog fa-spin' # 左侧显示的小图标 def has_delete_permission(self, *args, **kwargs): # 删除权限 if self.request.user.is_superuser: # 管理员才能增加 return True return False def has_add_permission(self, *args, **kwargs): if self.request.user.is_superuser: # 管理员才能增加 return True return False def has_change_permission(self, *args, **kwargs): if self.request.user.is_superuser: # 管理员才能修改 return True return False def queryset(self): qs = super(MachineAdmin, self).queryset() if self.request.user.is_superuser: # 管理员可以查看所有 return qs else: # 登录用户只能看到自己修改的数据 return qs.filter(master_id=self.request.user.last_name) xadmin.site.register(MallMachine, MallMachineAdmin)
61、使用nginx部署项目 先在/etc/nginx/sites-available中创建一个配置文件,文件名为test(注意没有后缀):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #设定虚拟主机配置 server { #侦听80端口 listen 80; listen 443 ssl; #定义使用 www.nginx.cn访问 #ssl on; server_name xxx.xxx.com; #定义服务器的默认网站根目录位置 root /root/项目名称; ssl_session_timeout 5m; ssl_certificate /etc/nginx/cert/xxx.pem; ssl_certificate_key /etc/nginx/cert/xxx.key; ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:ECDHE:ECDH:AES:HIGH:!NULL:!aNULL:!MD5:!ADH:!RC4; ssl_protocols TLSv1 TLSv1.1 TLSv1.2; ssl_prefer_server_ciphers on; #设定本虚拟主机的访问日志 #access_log logs/nginx.access.log main; #默认请求 location / { #倒入了uwsgi的配置 include uwsgi_params; client_max_body_size 50m; #连接uwsgi的超时时间 # uwsgi_connect_timeout 30; #设定了uwsig服务器位置 uwsgi_pass 127.0.0.1:8002; } location /static{ alias /root/项目名称/static; } location /media { alias /root/项目名称/media; } }
其中xxx.xxx.com表示域名.如果没有https,就使用#把ssl注释掉就可以了。
然后把test映射到/etc/nginx/sites-enabled
命令
1 2 ln -s /etc/nginx/sites-available/test /etc/nginx/sites-enabled/test
即可
1 django + uwsgi + nginx 日志Listen queue size is greater than the system max net.core.somaxconn (128).
解决方法:
1 2 3 4 修改系统参数 /proc/sys/net/ipv4/tcp_max_syn_backlog 原来2048 改为8192 /proc/sys/net/core/somaxconn 原来128 改为262144
重启nginx
62、xadmin后台发送邮件找回密码
输入你用户绑定的邮箱
想要发送邮件,需要在settings.py中设置邮件发送器
settings.py最下面增加
1 2 3 4 5 6 7 8 9 # ------------------------邮箱配置----------------------------------------- EMAIL_BACKEND = 'django.core.mail.backends.smtp.EmailBackend' #把要发送的邮件显示再控制台上,方便调试 EMAIL_USE_SSL = True EMAIL_HOST = 'smtp.qq.com' # 如果是 163 改成 smtp.163.com EMAIL_PORT = 465 EMAIL_HOST_USER = '邮箱账号' # 帐号 EMAIL_HOST_PASSWORD = '授权码' # 到邮箱里开通 DEFAULT_FROM_EMAIL = EMAIL_HOST_USER
由于django2与xadmin有些地方不兼容,需要修改源码:
找到虚拟环境根目录\Lib\site-packages\xadmin\plugins\passwords.py
在passwords.py文件中大概79行,修改为
1 2 3 4 5 6 7 8 9 return password_reset_confirm(request=request, uidb36=uidb36, token=token, template_name=self.password_reset_confirm_template, token_generator=self.password_reset_token_generator, set_password_form=self.password_reset_set_form, post_reset_redirect=self.get_admin_url('xadmin_password_reset_complete'), current_app=self.admin_site.name, extra_context=context).dispatch(request=request, uidb64=uidb36,token=token)
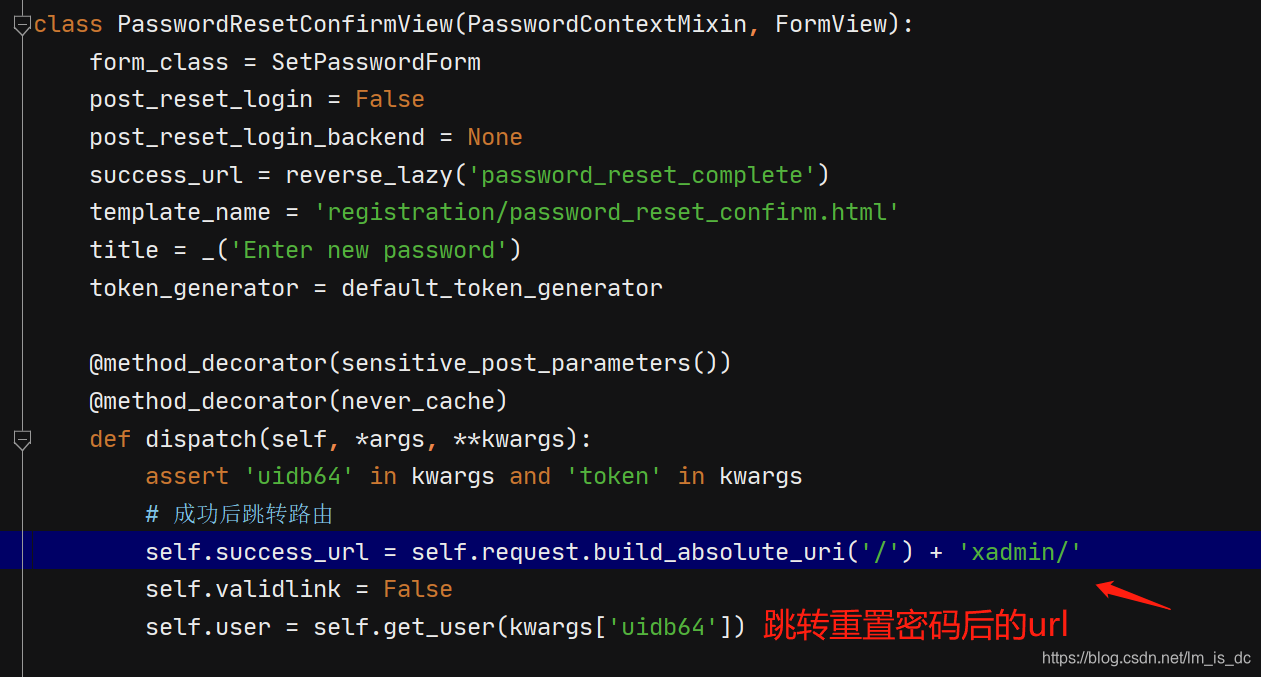
找到虚拟环境根目录Lib\site-packages\django\contrib\auth\views.py
在views.py文件中大概258行,增加:
1 2 3 # 成功后跳转路由,根据自己实际来定 self.success_url = self.request.build_absolute_uri('/') + 'xadmin/'
63、xadmin外键下拉框添加过滤 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class MallGoodsAdmin(object): """商品管理""" list_display = ['id', 'show_photo', 'nickname', 'merchant', 'goods_class', 'label',] search_fields = ['nickname'] list_filter = ['goods_class', 'label',] model_icon = 'fa fa-bars' list_editable = ['goods_class', ] #,重写虚拟环境根目录下\Lib\site-packages\xadmin\views\edit.py中的formfield_for_dbfield def formfield_for_dbfield(self, db_field, **kwargs): # 对MallGoodsClass这个表项的下拉框选择进行过滤 # MallGoods中有一个goods_class商品分类外键MallGoodsClass,过滤掉外键MallGoodsClass中 # master_class为空的值 if db_field.name == "goods_class": kwargs["queryset"] = MallGoodsClass.objects.filter(master_class__isnull=False) # 对assigned_recipient这个表项的下拉选择进行过滤 return db_field.formfield(**dict(**kwargs)) return super().formfield_for_dbfield(db_field, **kwargs) xadmin.site.register(models.MallGoods, MallGoodsAdmin)
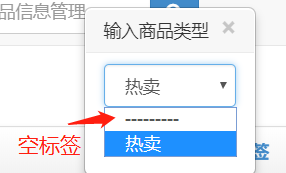
64、xadmin即时编辑器去掉空标签
虚拟环境根目录下\Lib\site-packages\xadmin\plugins\editable.py,在大概
129行增加:
1 2 form.fields[fields[0]].empty_label = None
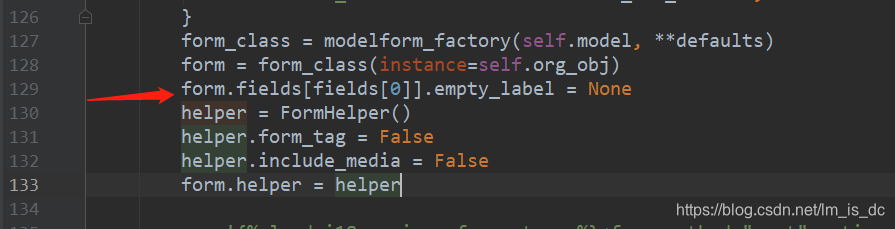
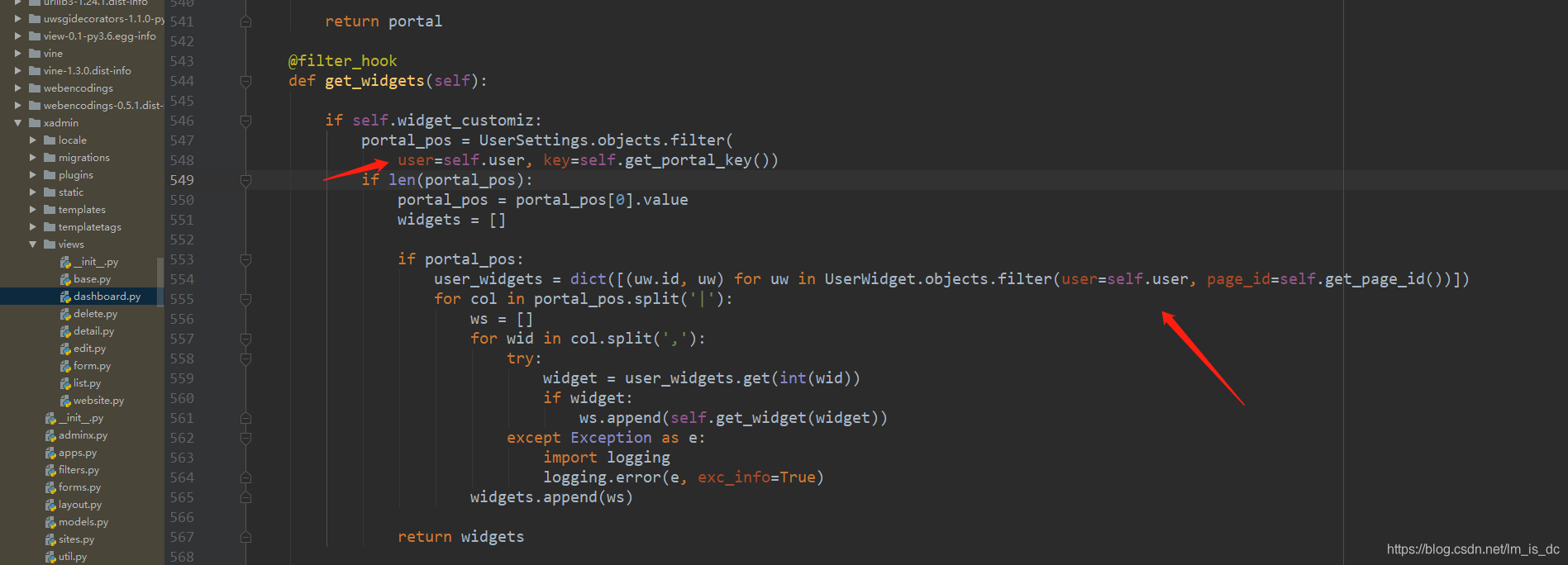
65、用户增加的小组件,让其他用户可见 找到虚拟环境根目录\Lib\site-packages\xadmin\views\dashboard.py
在548行、554行
改为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 @filter_hook def get_widgets(self): if self.widget_customiz: portal_pos = UserSettings.objects.filter( key=self.get_portal_key()) if len(portal_pos): portal_pos = portal_pos[0].value widgets = [] if portal_pos: user_widgets = dict([(uw.id, uw) for uw in UserWidget.objects.filter(page_id=self.get_page_id())]) for col in portal_pos.split('|'): ws = [] for wid in col.split(','): try: widget = user_widgets.get(int(wid)) if widget: ws.append(self.get_widget(widget)) except Exception as e: import logging logging.error(e, exc_info=True) widgets.append(ws) return widgets return self.get_init_widget()
66、pip install uwsgi出错 1 2 plugins/python/uwsgi_python.h:2:20: fatal error: Python.h: No such file or directory
首先安装python3环境
1 2 apt install python3-dev
然后再虚拟环境中
66、xadmin后台加载数据慢,解决方案 list_filter: 过滤器要慎用,不要使用类似id这些数据量大的字段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class MallUserAdmin(object): """用户管理""" list_display = ['id', 'tp_icon', 'nickname', 'phone', 'level', 'balance', 'province', 'city', 'quxian'] # 显示字段 search_fields = ['id', 'nickname', 'phone'] # 搜索 list_filter = ['level', 'province', 'city', 'quxian'] # 过滤器 # list_filter = ['id', 'level', 'province', 'city', 'quxian'] # 如果加id,xadmin加载回来的数据就会很慢,所以不要在过滤器上使用id list_per_page = 30 # 默认每页数量 model_icon = 'fa fa-users' # 左侧图标 ordering = ['-id'] # 排序 readonly_fields = ['subscribe', 'wx_openid', 'phone'] # 只读字段 is_addbalance = True # 加载自定义的插件 relfield_style = 'fk-ajax' # 其他表如果外键到用户表就做ajax搜索查询,不一次性加载数据
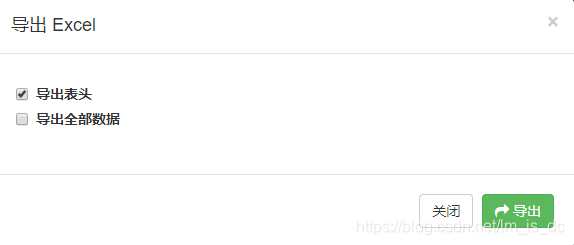
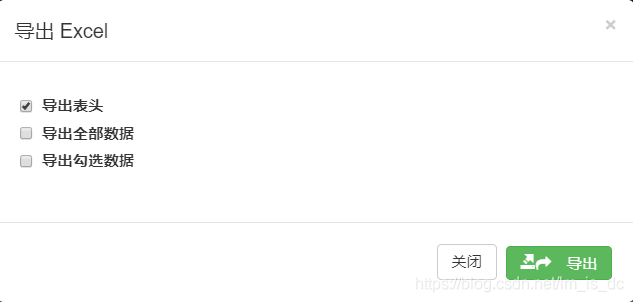
67 、xadmin导出插件处理,增加导出勾选数据项 常规的导出只有两个选择【导出表头】、【导出全部数据】
现在想要做的是增加一个选择,即【导出表头】、【导出全部数据】、【导出勾选数据】,如下图:
需要修改xadmin源代码,具体如下
1、加载js文件 找到虚拟环境\Lib\site-packages\xadmin\views\list.py,在607行增加’xadmin.plugin.importexport.js’,如下图所示
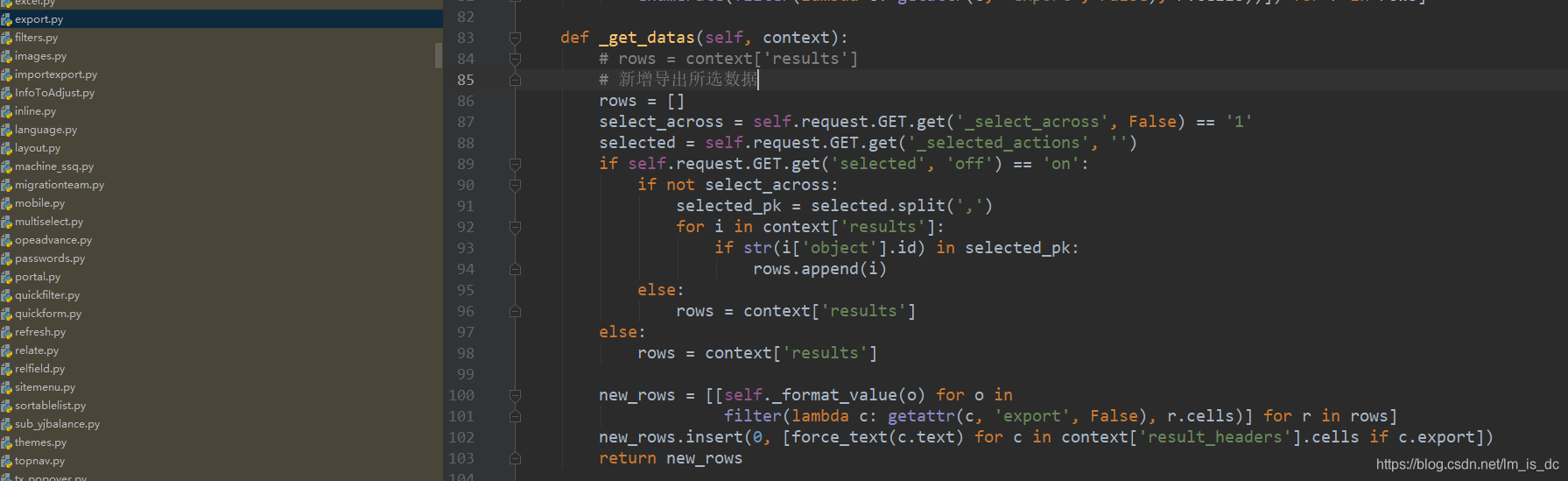
2、修改export.py,后端处理下载文件 找到虚拟环境\Lib\site-packages\xadmin\plugins\export.py
在84行把rows = context[‘results’]修改成如下函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # 新增导出所选数据 # rows = context['results'] rows = [] select_across = self.request.GET.get('_select_across', False) == '1' selected = self.request.GET.get('_selected_actions', '') if self.request.GET.get('selected', 'off') == 'on': if not select_across: selected_pk = selected.split(',') for i in context['results']: if str(i['object'].id) in selected_pk: rows.append(i) else: rows = context['results'] else: rows = context['results']
3、 修改model_list.top_toolbar.exports.html
使用以下代码覆盖原文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 {% load i18n %} <div class="btn-group export"> <a id="export-menu" class="dropdown-toggle btn btn-default btn-sm" data-toggle="dropdown" href="#"> <i class="fa fa-share"></i> {% trans "Export" %} <span class="caret"></span> </a> <ul class="dropdown-menu" role="menu" aria-labelledby="dLabel"> {% for et in export_types %} <li><a data-toggle="modal" data-target="#export-modal-{{et.type}}"><i class="fa fa-arrow-circle-down"> </i> {% trans "Export" %} {{et.name}}</a></li> {% endfor %} </ul> {% for et in export_types %} <div id="export-modal-{{et.type}}" class="modal fade"> <div class="modal-dialog"> <div class="modal-content"> <form method="get" action=""> <div class="modal-header"> <button type="button" class="close" data-dismiss="modal" aria-hidden="true">×</button> <h4 class="modal-title">{% trans "Export" %} {{et.name}}</h4> </div> <div class="modal-body"> {{ form_params|safe }} <input type="hidden" name="export_type" value="{{et.type}}"> <!-- 增加 导出所选数据 一栏 --> <input type="hidden" name="_selected_actions" value=""/> <input type="hidden" name="_select_across" value=""/> <label class="checkbox"> {% if et.type == "xlsx" %} <input type="checkbox" name="export_xlsx_header" checked="checked" value="on"> {% trans "Export with table header." %} {% endif %} {% if et.type == "xls" %} <input type="checkbox" name="export_xls_header" checked="checked" value="on"> {% trans "Export with table header." %} {% endif %} {% if et.type == "csv" %} <input type="checkbox" name="export_csv_header" checked="checked" value="on"> {% trans "Export with table header." %} {% endif %} {% if et.type == "xml" %} <input type="checkbox" name="export_xml_format" checked="checked" value="on"> {% trans "Export with format." %} {% endif %} {% if et.type == "json" %} <input type="checkbox" name="export_json_format" checked="checked" value="on"> {% trans "Export with format." %} {% endif %} </label> <label class="checkbox"> <input type="checkbox" name="all" value="on"> {% trans "Export all data." %} </label> <!-- 增加 导出所选数据 一栏 --> <label class="checkbox"> <input type="checkbox" name="selected" value="on"> 导出勾选数据 </label> </div> <div class="modal-footer"> <button type="button" class="btn btn-default" data-dismiss="modal">{% trans "Close" %}</button> <button class="btn btn-success myexport glyphicon glyphicon-export " type="submit"><i class="fa fa-share"></i> {% trans "Export" %} </button> </div> </form> </div><!-- /.modal-content --> </div><!-- /.modal-dalog --> </div><!-- /.modal --> {% endfor %} </div> <script type="text/javascript"> // 如果是订单导出,把待出货订单设置成待收货订单 $(document).ready(function () { $('.myexport').click(function () { // 当把订单导出时,需要修改订单状态为待收货状态 var url = window.location.protocol + '//' + window.location.host + "/exportorder/"; $("input[name='_select_across']").val($("input[name='select_across']").val()); if ($("input[name='selected']").is(':checked')) { var arr = []; $.each($('.action-select'), function () { if (true == $(this).prop('checked')) { arr.push($(this).val()); } }); if(arr.length == 0){ alert('请先勾选导出数据') return false } }else{ var arr = [] var order_type = $('.breadcrumb li').eq(1).text().trim() $('.grid-item').each(function (index, el) { arr.push($(el).find('td').eq(1).text().trim()) }) } if (($('.breadcrumb > li').eq(1).text()).indexOf('订单') != -1) { // 5秒后执行 setTimeout(function () { $.ajax({ type: "POST", url: url, data: {'orderlist': JSON.stringify(arr), 'order_type': order_type,}, beforeSend: function (xhr) { xhr.setRequestHeader("X-CSRFToken", $.getCookie("csrftoken")) }, success: function (data) { window.location.reload(); }, error: function (xhr) { alert("出现未知错误"); window.location.reload(); } }); }, 5000); } }); }) </script>
68、使用F查询更新用户重要数据 1 2 3 4 5 from django.db.models import F # 使用F查询更新用户余额 balance = 5 MallUser.objects.filter(id=1).update(balance=F('balance') + balance)
相当于sql的
1 2 update Malluser set balance=balance + 5 where id=1;
69、日志输出模块 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import logging import platform # 全局函数 PlATFORM = platform.system() if (PlATFORM == "Linux"): # linux系统,文件保存在var下 SERVER_LOG_PATH = '/var/mylog.log' else: # windows系统,文件保存在D盘下 SERVER_LOG_PATH = 'D:\mylog.log' # 定义一个logging的对象,命名为mylog LOGGER = logging.getLogger('mylog') # 设置级别为WARNING LOGGER.setLevel(logging.WARNING) # 创建一个handler,用于写入日志文件 fh = logging.FileHandler(SERVER_LOG_PATH, encoding='utf-8') fh.setLevel(logging.WARNING) # 定义handler的输出格式 formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s', datefmt='%Y-%m-%d %H:%M:%S') fh.setFormatter(formatter) # 给Logger添加handler LOGGER.addHandler(fh) # 不在控制台显示 LOGGER.propagate = False
70、字典排序 字典在内存中发布是无序的,当想对键值或者键名进行排序时可以先把字典转成元组,这可以达到排序的目的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 score = {'小明': {'avg_score': 90, 'English': 90, 'Math': 90, 'Chniese': 90, }, '小红': {'avg_score': 60, 'English': 60, 'Math': 61, 'Chniese': 59, }, '小黑': {'avg_score': 70, 'English': 75, 'Math': 65, 'Chniese': 70, }, '小白': {'avg_score': 80, 'English': 95, 'Math': 65, 'Chniese': 80, }, } # 对姓名进行排序,即对键名进行排序 b = sorted(score.items(), key=lambda x: x[0], reverse=True) show_str = '' for info in b: # print(info) key, value = info[0], info[1] show_str += '姓名:{},平均分:{},成绩:{}'.format(key,value['avg_score'], value) + '\r\n' print('对姓名进行排序') print(show_str) # 对平均分进行排序 b = sorted(score.items(), key=lambda x: x[1]['avg_score'], reverse=True) show_str = '' for info in b: # print(info) key, value = info[0], info[1] show_str += '姓名:{},平均分:{},成绩:{}'.format(key,value['avg_score'], value) + '\r\n' print('对平均分进行排序') print(show_str) # 对英语成绩进行排序 b = sorted(score.items(), key=lambda x: x[1]['English'], reverse=True) show_str = '' for info in b: # print(info) key, value = info[0], info[1] show_str += '姓名:{},平均分:{},成绩:{}'.format(key,value['avg_score'], value) + '\r\n' print('对英语成绩进行排序') print(show_str)
输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 对姓名进行排序 姓名:小黑,平均分:70,成绩:{'avg_score': 70, 'English': 75, 'Math': 65, 'Chniese': 70} 姓名:小红,平均分:60,成绩:{'avg_score': 60, 'English': 60, 'Math': 61, 'Chniese': 59} 姓名:小白,平均分:80,成绩:{'avg_score': 80, 'English': 95, 'Math': 65, 'Chniese': 80} 姓名:小明,平均分:90,成绩:{'avg_score': 90, 'English': 90, 'Math': 90, 'Chniese': 90} 对平均分进行排序 姓名:小明,平均分:90,成绩:{'avg_score': 90, 'English': 90, 'Math': 90, 'Chniese': 90} 姓名:小白,平均分:80,成绩:{'avg_score': 80, 'English': 95, 'Math': 65, 'Chniese': 80} 姓名:小黑,平均分:70,成绩:{'avg_score': 70, 'English': 75, 'Math': 65, 'Chniese': 70} 姓名:小红,平均分:60,成绩:{'avg_score': 60, 'English': 60, 'Math': 61, 'Chniese': 59} 对英语成绩进行排序 姓名:小白,平均分:80,成绩:{'avg_score': 80, 'English': 95, 'Math': 65, 'Chniese': 80} 姓名:小明,平均分:90,成绩:{'avg_score': 90, 'English': 90, 'Math': 90, 'Chniese': 90} 姓名:小黑,平均分:70,成绩:{'avg_score': 70, 'English': 75, 'Math': 65, 'Chniese': 70} 姓名:小红,平均分:60,成绩:{'avg_score': 60, 'English': 60, 'Math': 61, 'Chniese': 59}
对列表中字典按多个键值排序 1 2 3 4 5 6 7 8 9 10 11 12 13 14 from operator import itemgetter data = [ {'code': 1, 'position': 300, 'time': '1620442242'}, {'code': 2, 'position': 255, 'time': '1620442242'}, {'code': 3, 'position': 256, 'time': '1620442242'}, {'code': 1, 'position': 500, 'time': '1620442242'}, {'code': 5, 'position': 455, 'time': '1620442242'}, {'code': 1, 'position': 322, 'time': '1620442242'}, {'code': 6, 'position': 676, 'time': '1620442242'}, ] data = sorted(data, key=itemgetter('code', 'position')) print(data)
输出:
1 2 3 4 5 6 7 8 [ {'code': 1, 'position': 300, 'time': '1620442242'}, {'code': 1, 'position': 322, 'time': '1620442242'}, {'code': 1, 'position': 500, 'time': '1620442242'}, {'code': 2, 'position': 255, 'time': '1620442242'}, {'code': 3, 'position': 256, 'time': '1620442242'}, {'code': 5, 'position': 455, 'time': '1620442242'}, {'code': 6, 'position': 676, 'time': '1620442242'}]
71、时间格式与字符串互转、比较大小 1 2 3 4 5 6 7 8 9 10 import datetime # 当前时间转字符串 now = datetime.datetime.strftime(datetime.datetime.now(), '%Y-%m-%d %H:%M:%S') # 字符串转时间格式 now = datetime.datetime.strptime(now, '%Y-%m-%d %H:%M:%S') a = now + datetime.timedelta(minutes=-15) # 时间比较大小 if a < now: print('yes')
72、python把’\u’开头的字符串转中文 1 2 3 4 5 6 7 str_data = '\\u7528\\u6237 ID \\u6216\\u5bc6\\u7801\\u9519\\u8bef' # 字符串.encode('utf-8').decode('unicode_escape') str_data_to_zh = str_data.encode('utf-8').decode('unicode_escape') print(str_data_to_zh) # 输出 用户 ID 或密码错误
73、django进行数据迁移时出现No changes detected解决方案 原因:可能是由于app下面没有migrations文件夹
1 python manage.py makemigrations --empty 你的app名称
74、ubuntu下载文件到windows桌面 1 2 apt install lrzsz sz 123.txt
75、git查看提交日志 76、python翻译模块 可以把英文翻译成中文,也可以把中文翻译成英文
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 pip install translate from translate import Translator name = 'giant panda, panda, panda bear, coon bear, Ailuropoda melanoleuca' translator = Translator(to_lang="chinese") translation = translator.translate(name) print(translation) translator= Translator(from_lang="chinese",to_lang="english") translation = translator.translate("我想你") print(translation) 输出: 大熊猫,熊猫,熊猫熊,浣熊,大熊猫 I missed you.
77、python实现字符串转字典 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import ast import json target_str = '{"h": 1, "e": 2, "l": 3, "l": 4, "o": 5}' target_str2 = "{'h': 1, 'e': 2, 'l': 3, 'l': 4, 'o': 5}" # 方式1:使用json,缺点,字符串中不能出现单引号 # 由于 json 语法规定 数组或对象之中的字符串必须使用双引号,不能使用单引号 # 官网https://www.json.org/json-en.html上有一段描述是 # A string is a sequence of zero or more Unicode characters, wrapped in double quotes, using backslash escapes print(json.loads(target_str)) # print(json.loads(target_str2)) # 使用json转这个字符串会报错 Expecting property name enclosed in double quotes # 方式2:使用eval函数,缺点,不安全 print(eval(target_str)) print(eval(target_str2)) # print(eval("__import__('os').system('dir')")) # 会列出当前的目录文件,如果字符串是一些删除命令,则可以把整个目录清空! # 方式3,使用ast.literal_eval,没有json与eval的缺点,推荐使用这个 print(ast.literal_eval(target_str)) print(ast.literal_eval(target_str2))
输出:
1 2 3 4 5 {'h': 1, 'e': 2, 'l': 4, 'o': 5} {'h': 1, 'e': 2, 'l': 4, 'o': 5} {'h': 1, 'e': 2, 'l': 4, 'o': 5} {'h': 1, 'e': 2, 'l': 4, 'o': 5} {'h': 1, 'e': 2, 'l': 4, 'o': 5}
78、django app 如何在后台显示中文名 1.在app (这里以user为例)下面的__init__.py文件中
添加:
1 default_app_config = 'user.apps.UserConfig'
2.在apps.py中
1 2 3 4 5 from django.apps import AppConfig class UserConfig(AppConfig): name = 'user' verbose_name = '用户'
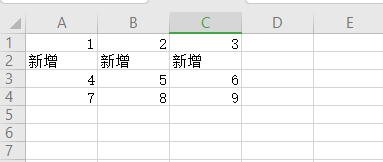
79、使用python给Excel指定行添加数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import openpyxl, sys wb = openpyxl.load_workbook('b.xlsx') sheet = wb['Sheet1'] # 在excel表格第二行添加新数据 addrow = 1 # 增加一行 row = 2 # 在第二行新增一行 name = 'b-back.xlsx' # 新的表名 wb1 = openpyxl.Workbook() sheet1 = wb1['Sheet'] # 复制前row行 for i in range(1, row): for j in range(1, sheet.max_column + 1): sheet1.cell(row=i, column=j).value = sheet.cell(row=i, column=j).value # 复制后row行 for i in range(row, sheet.max_row + 1): for j in range(1, sheet.max_column + 1): if i == row: # 给第row行添加新的数据 sheet1.cell(row=row, column=j).value = '新增' sheet1.cell(row=i + addrow, column=j).value = sheet.cell(row=i, column=j).value wb1.save(name)
1 2 3 4 5 d = {'a': 1, 'b': 2, 'c': 3, 'd': 5} print('{a},{b}'.format(**d)) print('{0},{1},{0}'.format('a', 'b')) print(f"{d['a']}")
输出:
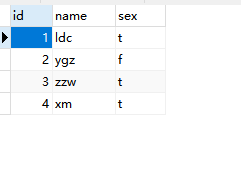
81、数据库inner join、full join、left join、union、union all区别 表a_test
表b_test
INNER JOIN
是A和B的交集
1 2 3 SELECT * FROM a_test INNER JOIN b_test ON a_test.name = b_test.namesa Inner join 产生的结果集中,是A和B的交集。
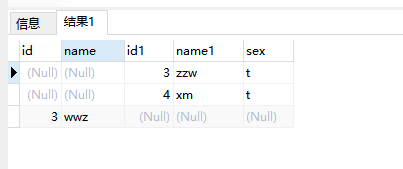
FULL OUTER JOIN
产生A和B的并集
1 2 3 4 5 SELECT * FROM a_test FULL OUTER JOIN b_test ON a_test.name = b_test.name Full outer join 产生A和B的并集。 但是需要注意的是,对于没有匹配的记录,则会以null做为值。 可以使用IF NULL判断。
1 2 3 4 SELECT * FROM a_test FULL OUTER JOIN b_test ON a_test.name = b_test.name WHERE a_test.id IS null OR b_test.id IS null 产生A表和B表没有交集的数据集。
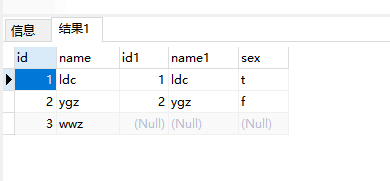
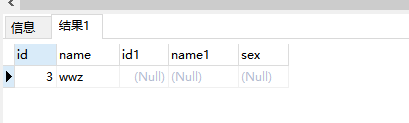
LEFT [OUTER] JOIN
产生表A的完全集,而B表中匹配的则有值,没有匹配的则以null值取代
1 2 3 4 SELECT * FROM a_test LEFT OUTER JOIN b_test ON a_test.name = b_test.name 有些数据库可以不要OUTER SELECT * FROM a_test LEFT JOIN b_test ON a_test.name = b_test.name Left outer join 产生表A的完全集,而B表中匹配的则有值,没有匹配的则以null值取代。
1 2 3 4 SELECT * FROM a_test LEFT OUTER JOIN b_test ON a_test.name = b_test.name WHERE b_test.id IS null 产生在A表中有而在B表中没有的集合。
RIGHT [OUTER] JOIN
RIGHT OUTER JOIN 是后面的表为基础,与LEFT OUTER JOIN用法类似。
UNION 与 UNION ALL
1 2 3 4 5 6 7 8 9 UNION 操作符用于合并两个或多个 SELECT 语句的结果集。 请注意,UNION 内部的 SELECT 语句必须拥有相同数量的列。 列也必须拥有相似的数据类型。 同时,每条 SELECT 语句中的列的顺序必须相同。 UNION 只选取记录,而UNION ALL会列出所有记录。 SELECT name FROM a_test UNION SELECT name FROM b_test 选取不同值
1 2 3 4 5 6 7 SELECT a_test.id,a_test.name FROM a_test UNION SELECT b_test.id,b_test.name FROM b_test 由于 id 51 xh 与 id 4 xh 并不相同,不合并
1 2 3 4 SELECT name FROM a_test UNION ALL SELECT name FROM b_test 全部列出来
还需要注意的是我们还有一个是“交差集” cross join, 这种Join没有办法用文式图表示,因为其就是把表A和表B的数据进行一个N*M的组合,即笛卡尔积。
表达式如下:SELECT * FROM a_test CROSS JOIN b_test
这个笛卡尔乘积会产生 4 x 4 = 16 条记录,一般来说,我们很少用到这个语法。但是我们得小心,如果不是使用嵌套的select语句,一般系统都会产生笛卡尔乘积然再做过滤。这是对于性能来说是非常危险的,尤其是表很大的时候。
82、windows电脑查看端口使用情况 找出8000端口对应的PID进程,命令为:
1 netstat -ano|findstr 8000
进程信息如下:
1 2 TCP 0.0.0.0:8000 0.0.0.0:0 LISTENING 1620 UDP 0.0.0.0:8000 *:* 1620
找出进程对应的详细信息:
1 2 3 tasklist |findstr 1620 KGService.exe 1620 Console 1 18,696 K
关进程:
查看程序占用内存
1 tasklist /fi "imagename eq python.exe"
83、Django生成表和反向生成Model 1 2 3 4 5 6 7 8 9 10 正向生成: python manage.py makemigrations python manage.py migrate 反向: 会根据设置的数据库中的表在自动生成对应的Model代码,并打印出来 python manage.py inspectdb 以直接将打印的代码直接导入到指定的Model文件中 python manage.py inspectdb > models.py
84、windows的hosts文件位置 1 C:\Windows\System32\drivers\etc\hosts
85、postgresql数据库 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 # 如果表存在就先删除 drop table if exists student; # 创建学生表 # id serial not null 表示id自增 # id integer not null 表示id不自增 create table student ( id serial not null constraint student_pk primary key, name varchar, class_id integer, height numeric, weight numeric, write_date timestamp ); comment on table student is '学生表'; comment on column student.name is '名称'; comment on column student.class_id is '班级ID'; comment on column student.height is '身高'; comment on column student.weight is '体重'; comment on column student.write_date is '修改时间'; alter table student owner to odoo; # 更新 update user set name='张三' where id=111 # 更新表a的字段为表b的值 update account_invoice set sale_order_id=so.id from sale_order so where account_invoice.origin=so.name # 新增 insert into "user" (name,sex) values ('小明',1),('小红', 0) # 新增或更新 如果id冲突就更新 INSERT INTO student(id, name) VALUES(12, '小明'),(13, '小红') ON conflict(id) DO UPDATE SET name ='未知'; 如果id冲突就什么也不做 INSERT INTO student(id, name) VALUES(12, '小明'),(13, '小红') ON conflict(id) DO NOTHING; # 把一个表中的数据插入到另一个表中 insert into 目标表名 (column1,column2,columnn) select value1,value2,valuen from 源表名 比如: insert into student (name, classs_name,create_date) select student_name as name, class_name, now() from class_table; # 获取当前时间 now() select now() # 删除 DELETE FROM table_name [WHERE Clause] # 增加字段 alter table 表名 add column 列名 类型; # 删除字段 alter table 表名 dropcolumn 列名 ; # postgresql数据库查看表所有字段 select * from information_schema.columns where table_schema='public' and table_name='表名'; # postgresql获取所有表名 select tablename from pg_tables where schemaname='public' # 对查询结果按id降序显示 select * from table_name order by id desc # 对查询结果按id升序显示 select * from table_name order by id asc # 转义字符, 查找name中包含单引号的记录 select * from student where name like E'%\'%'; # 查看表记录总数 select relname as TABLE_NAME, reltuples as rowCounts from pg_class where relkind = 'r' and relnamespace = (select oid from pg_namespace where nspname='public') order by rowCounts desc; # 将结果转换为数组 SELECT array(SELECT "name" FROM sale_order); # 将数组合并为字符串 select array_to_string(array[1,2,3], ',') # 联合子集更新,把sale_order_line的name连接换行符,然后按id更新到表a_test中对应的name update a_test set name=array_to_string(array(select name from sale_order_line where order_id=a_test.id),'<br/>'); # PostgreSQL合并查询同一列的多条记录,针对一对多,多对多字段 比如表: id name 1 小明 1 小红 id name 1 小亮 --> 1 小明,小亮,小红 2 小强 2 小强,小王 2 小王 SELECT id, array_to_string(ARRAY(SELECT unnest(array_agg(name order by name desc))),',') AS all_name FROM student GROUP BY id; # case语句 case var when condition1 then statement1 when condition2 then statement2 else statementn end as new_name 比如: select case name when '小明' then 'xm' when '小红' then 'xh' when '小刚' then 'xg' else 'xw' end as short_name from student # 临时表、字符串合并、类型转换、时间格式转换、当前时间 WITH TEMP AS ( SELECT CAST ( concat ( bam.account_period_code, '-01' ) AS TIMESTAMP ) AS account_period_time FROM bi_account_move AS bam ) SELECT account_period_time, to_char(CURRENT_DATE,'yyyy-MM-dd hh24:MI:ss') as current_date, to_char( account_period_time, 'yyyy' ) as year, to_char( account_period_time, 'MM' ) as month, to_char( account_period_time, 'dd' ) as day FROM TEMP 比如: account_period_time current_date year month day 2019-06-01 0:00:00 2020-06-24 00:00:00 2019 06 01 2019-06-01 0:00:00 2020-06-24 00:00:00 2019 06 01 # 多个字符串拼接 select concat('payment_', CAST(ap.id as varchar)) as line_key from ap # 将查询所得结果集的某一字段拼接成字符串,默认的是逗号 select GROUP_CONCAT(id) from test where id>5; 结果为: 1,2,3,4,5,6,7 # 使用其他分隔符拼接 select GROUP_CONCAT(id separator '-') from test where id>5; 结果为: 1-2-3-4-5-6-7 # 多个临时表 WITH temp_student AS ( SELECT ID, NAME, sex FROM student WHERE sex = TRUE ), temp_class AS ( SELECT ID, NAME, student_id, teacher_id FROM the_class ), temp_teacher AS ( SELECT ID, NAME, age FROM teacher ) SELECT ts.NAME AS student_name, tc.NAME AS class_name, te.NAME AS teacher_name from temp_student as ts LEFT JOIN temp_class AS tc ON tc.student_id = ts.ID LEFT JOIN teacher AS te ON te.id = tc.teacher_id # null转成有意义的值 select COALESCE(name, '') as name from a_test 意思就是如果name为null,就转为空字符串 # 字符串截取 select SUBSTRING('abcd',1,2); -- result:ab 表示从下标从1开始,截取2个字符 # 使用 interval 时间相加减(+/-) 当前时间 + 10秒, select to_char(now() + interval '10 second', 'yyyy-mm-dd hh24:mi:ss') as reqDate from account_period; 当前时间 - 10秒 select to_char(now() + interval '-10 second', 'yyyy-mm-dd hh24:mi:ss') as reqDate from account_period; 当前时间 + 10分, select to_char(now() + interval '10 minute', 'yyyy-mm-dd hh24:mi:ss') as reqDate from account_period; 当前时间 + 10时, select to_char(now() + interval '10 hour', 'yyyy-mm-dd hh24:mi:ss') as reqDate from account_period; 当前时间 + 10天, select to_char(now() + interval '10 day', 'yyyy-mm-dd hh24:mi:ss') as reqDate from account_period; 当前时间 + 10年, select to_char(now() + interval '10 year', 'yyyy-mm-dd hh24:mi:ss') as reqDate from account_period; # UNION types numeric and text cannot be matched NULL::NUMERIC 这个问题,是因为几个sql组合在一起时,同一个字段的值,遇到null时,需要进行类型转换。 # 对行记录定义行编号,使用函数ROW_NUMBER() # 按分数进行降序,然后给行记录标记行编号,可以作为排名来使用 select ROW_NUMBER() OVER (ORDER BY score desc) AS sequence_number, name,score from b_test # 数字转字符串 select cast(123 as VARCHAR); # 字符串转数字 select cast('123' as INTEGER);
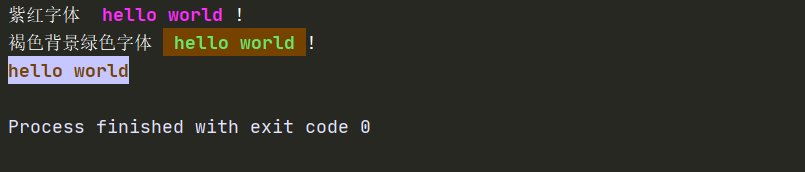
86、python控制台输出带颜色的文字方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #格式: 设置颜色开始 :\033[显示方式;前景色;背景色m #说明: 前景色 背景色 颜色 --------------------------------------- 30 40 黑色 31 41 红色 32 42 绿色 33 43 黃色 34 44 蓝色 35 45 紫红色 36 46 青蓝色 37 47 白色 显示方式 意义 ------------------------- 0 终端默认设置 1 高亮显示 4 使用下划线 5 闪烁 7 反白显示 8 不可见 #例子: \033[1;31;40m <!--1-高亮显示 31-前景色红色 40-背景色黑色--> \033[0m <!--采用终端默认设置,即取消颜色设置-->
1 2 3 4 例子 print('紫红字体 \033[1;35m hello world \033[0m!') print('褐色背景绿色字体 \033[1;32;43m hello world \033[0m!') print('\033[1;33;44mhello world\033[0m')
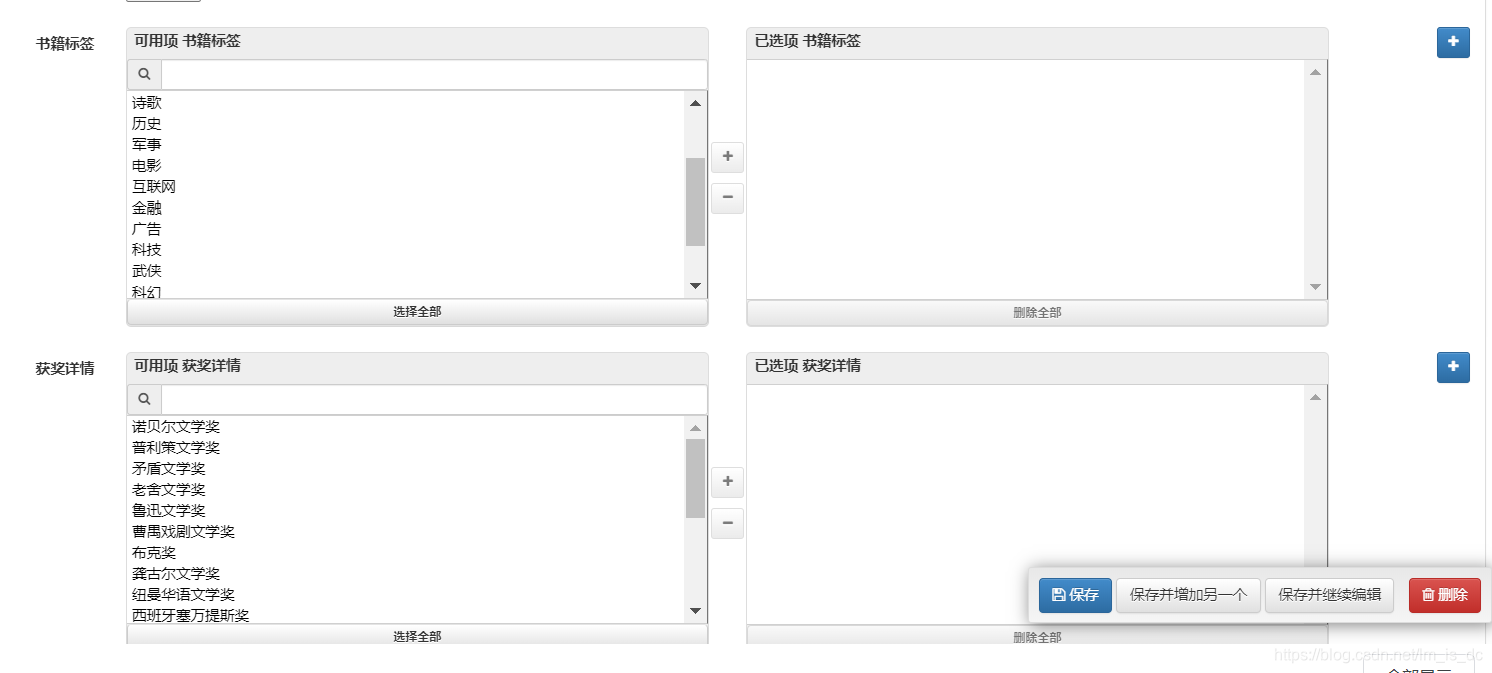
87、控制台输出白色方框 88、xadmin后台编辑多对多字段 在models.py定义了多对多字段,想要在编辑时可以灵活使用这个字段的话,可以按以下方法设置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Book(models.Model): title = models.CharField(verbose_name="书名", max_length=32) second_title = models.CharField(verbose_name="副标题", max_length=32, blank=True, null=True) author = models.CharField(verbose_name="作者", max_length=32) translator = models.CharField(verbose_name="译者", max_length=32, blank=True, null=True) intro = models.TextField(verbose_name="描述") pic = models.FileField(verbose_name="封面图片", max_length=64, upload_to='book_cover', null=True, blank=True) tags = models.ManyToManyField(Tags, verbose_name='书籍标签', blank=True) prizes = models.ManyToManyField(Prizes, verbose_name='获奖详情', blank=True) sump = models.IntegerField(verbose_name="收藏人数", default=0) rate_num = models.IntegerField(verbose_name="评分人数", default=0) num = models.IntegerField(verbose_name="浏览量", default=0) published_time = models.DateField(blank=True, null=True, verbose_name='出版时间') create_time = models.DateTimeField(auto_now_add=True, verbose_name='创建时间') class Meta: db_table = 'book' verbose_name = "图书" verbose_name_plural = "图书" def __str__(self): return self.title
adminx.py
1 2 3 4 5 6 7 8 9 10 11 12 # 书籍管理 class BookAdmin(object): search_fields = ['title', 'author', 'intro'] # 检索字段 list_display = ['id', 'show_pic', 'title', 'second_title', 'author', 'translator', 'published_time', 'intro', 'tags', 'prizes', 'num', 'sump', 'rate_num'] # 要显示的字段 list_filter = ['published_time', 'tags', 'prizes'] # 分组过滤的字段 ordering = ('id',) # 设置默认排序字段,负号表示降序排序 list_per_page = 30 # 默认每页显示多少条记录,默认是100条 model_icon = 'fa fa-book' # 左侧小图标 list_editable = ['title', 'author', 'intro', 'published_time'] # 可编辑字段 style_fields = {'tags': 'm2m_transfer', 'prizes': 'm2m_transfer'} # 控制字段的显示样式 filter_horizontal = ('tags', 'prizes') # 水平选择编辑多对多字段
重点是设置style_fields 和filter_horizontal ,效果:
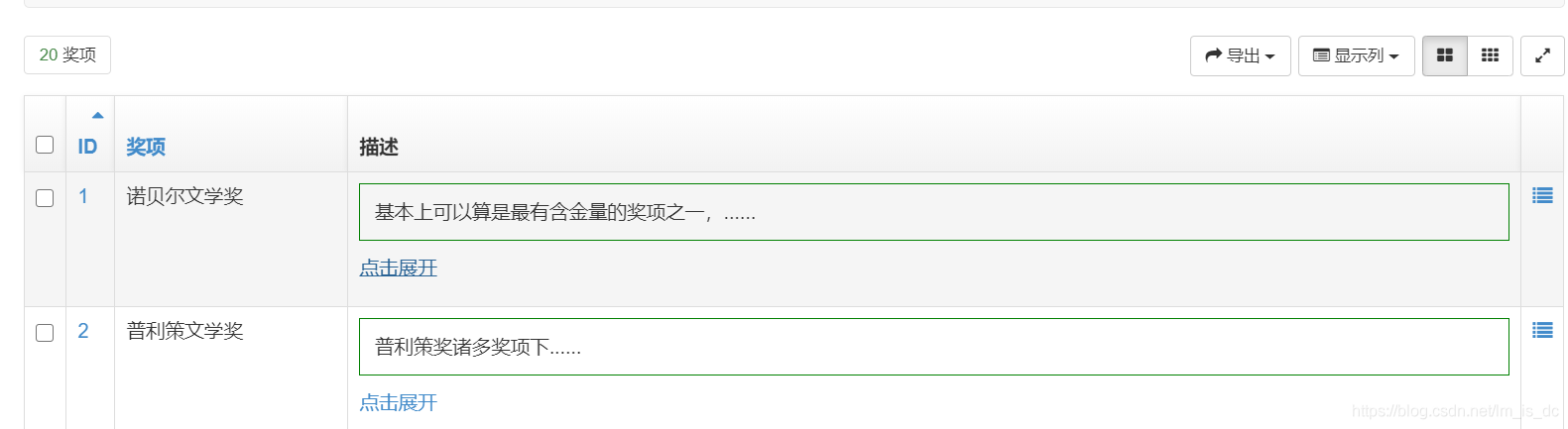
89、Django后台通过按钮显示TextField字段内容 由于TextField字段类型内容可能很长,在后台显示时很占屏幕位置,可以通过按钮来控制显示,代码如下:
1 2 3 4 5 6 7 8 9 10 11 class Prizes(models.Model): name = models.CharField(max_length=32, verbose_name="奖项") intro = models.TextField(blank=True, null=True, verbose_name='简介') class Meta: db_table = 'prizes' verbose_name = "奖项" verbose_name_plural = "奖项" def __str__(self): return self.name
这里使用xadmin作为后台管理框架,在adminx.py中代码如下:
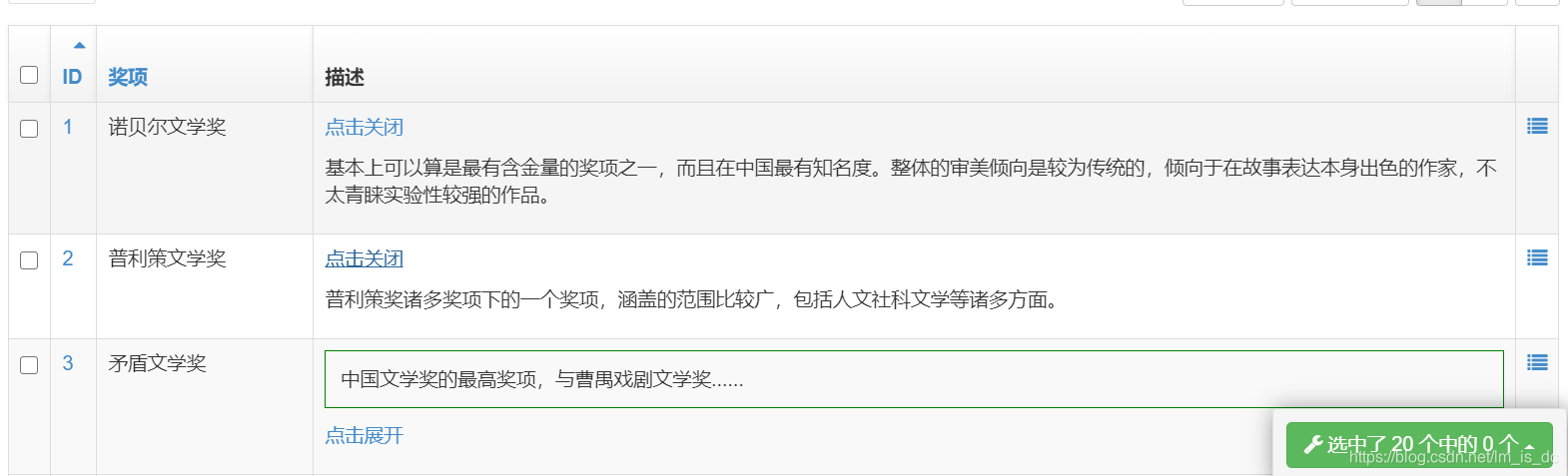
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 import xadmin from django.utils.safestring import mark_safe from xadmin import views from .models import * # 奖项管理 class PrizesAdmin(object): search_fields = ['name'] # 检索字段 list_display = ['id', 'name', 'show_intro'] list_filter = ['name'] ordering = ('id',) def show_intro(self, obj): # 显示简介 if not obj.intro: return mark_safe('') if len(obj.intro) < 20: return mark_safe(obj.intro) short_id = f'{obj._meta.db_table}_short_text_{obj.id}' short_text_len = len(obj.intro) // 4 short_text = obj.intro[:short_text_len] + '......' detail_id = f'{obj._meta.db_table}_detail_text_{obj.id}' detail_text = obj.intro text = """<style type="text/css"> #%s,%s {padding:10px;border:1px solid green;} </style> <script type="text/javascript"> function openShutManager(oSourceObj,oTargetObj,shutAble,oOpenTip,oShutTip,oShortObj){ var sourceObj = typeof oSourceObj == "string" ? document.getElementById(oSourceObj) : oSourceObj; var targetObj = typeof oTargetObj == "string" ? document.getElementById(oTargetObj) : oTargetObj; var shortObj = typeof oShortObj == "string" ? document.getElementById(oShortObj) : oShortObj; var openTip = oOpenTip || ""; var shutTip = oShutTip || ""; if(targetObj.style.display!="none"){ if(shutAble) return; targetObj.style.display="none"; shortObj.style.display="block"; if(openTip && shutTip){ sourceObj.innerHTML = shutTip; } } else { targetObj.style.display="block"; shortObj.style.display="none"; if(openTip && shutTip){ sourceObj.innerHTML = openTip; } } } </script> <p id="%s">%s</p> <p><a href="###" οnclick="openShutManager(this,'%s',false,'点击关闭','点击展开','%s')">点击展开</a></p> <p id="%s" style="display:none"> %s </p> """ % (short_id, detail_id, short_id, short_text, detail_id, short_id, detail_id, detail_text) return mark_safe(text) show_intro.short_description = '描述'
注意 :复制代码后需要做如下修改:
一开始效果
点击展开效果:
90、前端判断上传的文件是否为图片且限制大小为300kB 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 <!DOCTYPE html> <html lang="en-us"> <body class="login"> <input class="form-control input-lg" id="id_icon" name="icon" type="file" onchange="imgTypeSize('id_icon',300)" <script type="text/javascript"> //判断是否为图片,若为图片,判断其大小是否大于0.3M function imgTypeSize(FileId, maxsize) { /*获取图片内容对象*/ var imgFile = document.getElementById(FileId).files[0]; if (imgFile.name == "") { alert("请上传头像哦"); return false; } else { /*图片类型正则验证*/ var imgStr = /\.(jpg|jpeg|png|bmp|BMP|JPG|PNG|JPEG)$/; if (!imgStr.test(imgFile.name)) { alert("文件不是图片类型"); return false; } else { /*图片大小*/ var imagSize = imgFile.size; if (imagSize < (1024 * maxsize)) { return true; } else { alert(imgFile.name + "大小不能超过" + maxsize + "kB"); document.getElementById(FileId).value = "" return false; } } } } </script> </body> </html>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 <form action="" method="post" id="login-form" onsubmit="return toVaild()"> <input class="form-control" id="id_account" name="account" type="text" placeholder="账号"/> <input class="form-control" id="id_password" name="password" type="password" placeholder="密码"> <form> <script type="text/javascript"> document.getElementById('id_username').focus() function toVaild() { var account = document.getElementById("id_account").value; var password = document.getElementById("id_password").value; if (account == "" || password == "") { alert("请输入账号和密码"); return false; } else { return true; } } </script>
92、有序字典 1 2 3 4 5 6 7 8 9 import collections d1 = collections.OrderedDict() # 创建一个有序字典 d1['a'] = 'A' d1['b'] = 'B' d1['c'] = 'C' d1['d'] = 'D' for k, v in d1.items(): print(k, v)
93、Python在Windows系统下实现TTS(文字转语音) 导入包:
1 2 3 4 5 6 pip install pypiwin32 import win32com.client spk = win32com.client.Dispatch("SAPI.SpVoice") spk.Speak(u"my name is ldc,what is your name") spk.Speak(u"大家好")
94、定义一个简单闹钟 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 # pip install pypiwin32 -i https://pypi.python.org/simple import win32com.client import time import winsound spk = win32com.client.Dispatch("SAPI.SpVoice") # 定义闹钟时间 clocktime = [[19, 19], [11, 10], [12, 10], [18, 47]] runinghour = 1 # 定义运行时间 times = runinghour * 3600 # 次数 print(times) for i in range(1, times): time_now = [time.localtime(time.time()).tm_hour, time.localtime(time.time()).tm_min] if time_now in clocktime: print(time_now) winsound.Beep(1000, 1000) spk.Speak(u"快去看下饭好了没有?") time.sleep(60) # 每分钟对比一次时间
95、根据年月获取当月天数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 def get_month_days(year, month): """ 根据年份,月份信息显示此月份天数 :param year: 年份: :param month: 月份(1~12): :return: 当月天数 """ if month >12 or month <= 0: return -1 if month == 2: return 29 if year % 4 == 0 and year % 100 != 0 or year % 400 == 0 else 28 if month in (4, 6, 9, 11): return 30 else: return 31 a = '2020-04'.split('-') year = int(a[0]) month = int(a[1]) print(get_month_days(year,month)) 输出: 30
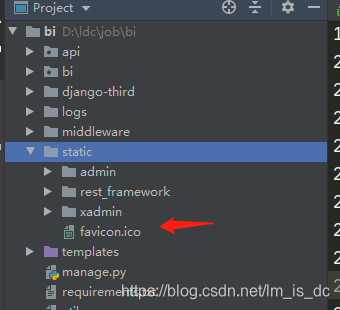
96、Django获取favicon.ico图标 制作一个ico文件,使用PS或者某些在线生成ico的网站
将此文件命名为“favicon.ico”后放在static/下
在urls.py中定义路由:
1 2 3 4 5 6 7 8 from django.urls import path from django.views.generic import RedirectView urlpatterns = [ # 访问favicon.ico 网站图标 path("favicon.ico",RedirectView.as_view(url='static/favicon.ico')), ]
97、django 静态文件配置 settings.py
1 2 3 4 5 6 7 8 9 STATIC_URL = '/static/' # 添加静态资源路由地址 STATICFILES_DIRS = [ os.path.join(BASE_DIR, 'static'), ] # 使用python manage.py collectstatic收集静态文件时时使用STATIC_ROOT # STATIC_ROOT = os.path.join(BASE_DIR, 'static')
urls.py
from django.urls import path, re_path
from django.views.generic import RedirectView
from django.views.static import serve
from '你的项目名称' import settings
urlpatterns = [
path("favicon.ico",RedirectView.as_view(url='static/favicon.ico')),
re_path('static/(?P<path>.*)$', serve, {'document_root': settings.STATICFILES_DIRS[0]}),
]
98、django JsonResponse返回中文时显示unicode编码(\u67e5\u8be2) 原因
解决方案
1 2 data = {'msg': '创建成功',} return JsonResponse(data=data, json_dumps_params={'ensure_ascii': False})
99、获取当前时间月份的首日与最后一天 1 2 3 4 5 6 7 8 9 10 11 12 import calendar def get_month_start_and_end(date=datetime.datetime.now()): """ 获取当前时间的月份首日与最后一天 :param date: :return: (首日,最后一天) """ year, month = str(date).split('-')[0], str(date).split('-')[1] end = calendar.monthrange(int(year), int(month))[1] return f'{year}-{month}-01', f'{year}-{month}-{end}'
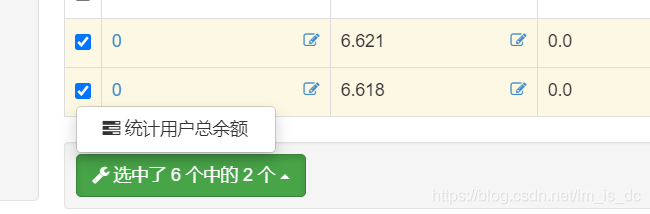
100、xadmin后台批量操作 adminx.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import xadmin from django.db.models import Sum from xadmin.plugins.actions import BaseActionView class MyCountFeeAction(BaseActionView): """ 用户余额统计 """ action_name = "countuserfee" #: 相当于这个 Action 的唯一标示, 尽量用比较针对性的名字 description = u'统计用户总余额' #: 描述, 出现在 Action 菜单中, 可以使用 ``%(verbose_name_plural)s`` 代替 Model 的名字. model_perm = 'view' # 权限 def do_action(self, queryset): all_balance = MallUser.objects.all().aggregate(Sum('balance')) return HttpResponse(f'用户总余额{all_balance}') class UserAdmin(object): """用户信息管理""" list_display = ['username', 'balance', 'status', 'addtime'] search_fields = ['username', ] list_filter = ['status', 'addtime'] list_per_page = 30 # 默认每页数量 model_icon = 'fa fa-user' list_editable = ['status'] ordering = ['-addtime'] actions = [ MyCountFeeAction] # 添加批量选择操作
101、xadmin过滤器外键显示特定值(比如只能过滤自己与超级管理员定义的数据) 首先,修改xadmin源码,修改xadmin/filters.py,在401行,做如下修改,
把self.lookup_choices = field.get_choices(include_blank=False)
改为:
# 调用自定义的方法
if hasattr(model_admin, '{field}_choices'.format(field=field.name)):
self.lookup_choices = getattr(model_admin, '{field}_choices'.format(field=field.name))(field, request,params, model,model_admin,field_path)
else:
self.lookup_choices = field.get_choices(include_blank=False)
如图:
然后,在adminx.py中定义过滤的方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import xadmin from django.db.models import Q, Sum from xadmin.plugins.actions import BaseActionView class MeasurePointAdmin(object): # search_fields = ['user__name', 'user__account'] # 检索字段 list_display = ['num', 'elevation', 'correct_num', 'cumulative_amount'] list_filter = ['user', 'is_default', 'create_time'] # 分组过滤的字段 list_editable = ['num', 'elevation', 'correct_num', 'cumulative_amount'] ordering = ('id',) # 设置默认排序字段,负号表示降序排序 list_per_page = 30 # 默认每页显示多少条记录,默认是100条 model_icon = 'fa fa-users' # 左侧小图标 readonly_fields = ['user', 'is_default'] import_excel = True actions = [MyCountFeeAction] # 定义的函数名必须是 字段名_choices def user_choices(self, field, request, params, model, model_admin, field_path): # 超级用户不做控制 if self.request.user.is_superuser: return field.get_choices(include_blank=False) # 过滤器只显示自己与超级管理员 user_lst = field.related_model._default_manager.filter(Q(id=self.request.user.id) | Q(is_superuser=True)) # 返回格式 [('pk','标题'),] return [(user.id, user.username) for user in user_lst]
效果:
102、Django中的CSRF局部禁用 为了避免没有csrf token而产生的403的forbidden错误,可以使用csrf_exempt装饰器来处理POST、GET请求的View, 这种方式是CSRF局部禁用。
1 2 3 4 5 6 7 8 9 10 from django.utils.decorators import method_decorator from django.views.decorators.csrf import csrf_exempt @method_decorator(csrf_exempt) def update_data(request): if request.method == 'POST': pass elif request.method == 'GET': pass
103、使用python命令创建django项目 创建django项目https://pypi.tuna.tsinghua.edu.cn/simple
104、 二维列表、二维数组行求和与列求和 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import pandas as pd from functools import reduce # 二维数组,对列和行求和 a = [ ['', 0, '', 1, 4.1], ['', 0, '', '', 4], ['123', 0, '', 3, 4, 6,7], ] def aa(x, y): x = 0 if isinstance(x, str) else x y = 0 if isinstance(y, str) else y return x + y # 对行求和 row_sum = [reduce(aa, i) for i in a] # 对列求和,只能处理相同长度的子元素 column_sum_1 = [reduce(aa, i) for i in zip(*a)] # 对列求和,可以处理不同长度的子元素 column_sum_2 = list(dict(pd.DataFrame(a).fillna(0).apply(lambda x: '' if any(isinstance(d, str) for d in x) else round(x.sum(), 2))).values()) print('行求和:{}\r\n列求和(相同长度):{}\r\n列求和:{}'.format(row_sum, column_sum_1, column_sum_2))
输出:
1 2 3 行求和:[5.1, 4, 20] 列求和(相同长度):[0, 0, 0, 4, 12.1] 列求和:['', 0, '', '', 12.1, 6.0, 7.0]
105、获取时间字符串的月份数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from datetime import datetime def get_months(start_month_str, end_month_str): ''' # 获取时间字符串中的月份数 :param start_month_str: 开始字符串 :param end_month_str: 结束字符串 :return: 月份数 ''' end_month_date = datetime.strptime(end_month_str, '%Y-%m') start_month_date = datetime.strptime(start_month_str, '%Y-%m') end_year, end_month = end_month_date.year, end_month_date.month start_year, start_month = start_month_date.year, start_month_date.month return (end_year - start_year) *12 + (end_month - start_month) + 1 end_month_str = '2021-02' start_month_str = '2020-07' print(get_months(start_month_str, end_month_str)) 输出: 8
106、字符串不足补零 1 2 3 4 5 6 7 8 9 print('hello world'.zfill(15)) # 补0 print('hello world'.rjust(15)) # 右对齐,补空格 print('hello world'.ljust(15)) # 左对齐,补空格 输出: 0000hello world hello world hello world
107、时间戳转字符串日期 1 2 3 4 5 6 7 8 import timet1 = time.time() print (t1)print (time.strftime("%Y-%m-%d %H:%M:%S" , time.localtime(t1)))输出: 1621741567.082192 2021 -05-23 11 :46 :07
使用函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 # !/usr/bin/python # -*- coding: utf-8 -*- """ @contact: 微信 1257309054 @file: 时间戳转日期.py @time: 2022/6/27 17:16 @author: LDC """ import time import datetime # 正确10位长度的时间戳可精确到秒,11-14位长度则是包含了毫秒 def int_to_datetime(intValue): if len(str(intValue)) == 10: # 精确到秒 timeValue = time.localtime(intValue) tempDate = time.strftime("%Y-%m-%d %H:%M:%S", timeValue) datetimeValue = datetime.datetime.strptime(tempDate, "%Y-%m-%d %H:%M:%S") elif 10 < len(str(intValue)) and len(str(intValue)) < 15: # 精确到毫秒 k = len(str(intValue)) - 10 timetamp = datetime.datetime.fromtimestamp(intValue / (1 * 10 ** k)) datetimeValue = timetamp.strftime("%Y-%m-%d %H:%M:%S.%f") else: return -1 return datetimeValue time1 = 1656321420 time2 = 1656321086560 print(int_to_datetime(time1)) print(int_to_datetime(time2)) ''' 输出: 2022-06-27 17:17:00 2022-06-27 17:11:26.560000 '''
108、列表转字符串 1 2 3 4 5 a = [1 ,2 ,3 ] print (',' .join(map (str ,a)))输出: `1 ,2 ,3 `
109、pip国内镜像源 1 2 3 4 5 6 7 8 9 10 11 12 13 14 pip install 库名 -i https://pypi.tuna.tsinghua.edu.cn/simple 清华:-i https://pypi.tuna.tsinghua.edu.cn/simple 阿里云:-i http://mirrors.aliyun.com/pypi/simple/ 中国科技大学 -i https://pypi.mirrors.ustc.edu.cn/simple/ 华中理工大学:-i http://pypi.hustunique.com/ 山东理工大学:-i http://pypi.sdutlinux.org/ 豆瓣:-i http://pypi.douban.com/simple/
110、python把时间字符串转换成刚刚、1天前、3个月前、1年前 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 import datetime import time def date_interval(date_str): ''' 获取时间间隔 1分钟前,2分钟前,10分钟前,1小时前,2小时前,1天前,2天前,3天前,1个月前,3个月前,1年前,3年前 :param date_str: 时间字符串 :return: 字符串 ''' date_str = time.strptime(date_str, '%Y-%m-%d %H:%M:%S') # 将时间元组转换为时间戳 t = time.mktime(date_str) # 当前时间 seconds = time.time() - t years = int(seconds // (60 * 60 * 24 * 365)) if years: return '{}年前'.format(years) months = int(seconds // (60 * 60 * 24 * 30)) if months: return '{}月前'.format(months) days = int(seconds // (60 * 60 * 24)) if days: return '{}天前'.format(days) hours = int(seconds // (60 * 60)) if hours: return '{}小时前'.format(hours) minutes = int(seconds // (60)) if minutes: return '{}分钟前'.format(minutes) return '刚刚' if __name__ == '__main__': date1 = '2019-07-10 15:27:51' date2 = '2021-07-10 15:27:51' date3 = '2021-08-10 15:27:51' date4 = '2021-08-12 11:01:51' date5 = datetime.datetime.now() + datetime.timedelta(seconds=-3) date5 = date5.strftime('%Y-%m-%d %H:%M:%S') print(date_interval(date1)) print(date_interval(date2)) print(date_interval(date3)) print(date_interval(date4)) print(date_interval(date5))
111、Django使用ORM执行sql语句 通过raw函数执行
1 2 3 4 5 6 7 8 9 10 11 alarm_datas = gsm.AlertMessage.objects.raw(''' select am_all.id, am_all.sensor_number FROM alert_message as am_all where am_all.real='1' and am_all.is_show=1 order by am_all.alarm_level desc ''') for ad in alarm_datas: print(ad.sensor_number)
112、Django通过变量字段获取数据 通过方法__getattribute__来获取
1 2 3 4 5 6 alert_messages = AlertMessage.objects.filter(real=0) am_fields = ['id', 'real', 'name'] for am in alert_messages: for i in range(len(am_fields)): print(am_fields[i], am.__getattribute__(am_fields[i]))
113、Django查询变量字段、更新变量字段 通过**{变量名:值}来操作
1 2 3 4 5 6 field = 'device_code' # 查询 device_infos = gsm.DeviceInfo.objects.filter(**{field: '012'}) # 更新 gsm.DeviceInfo.objects.filter(device_code='012').update(**{field : '0'})
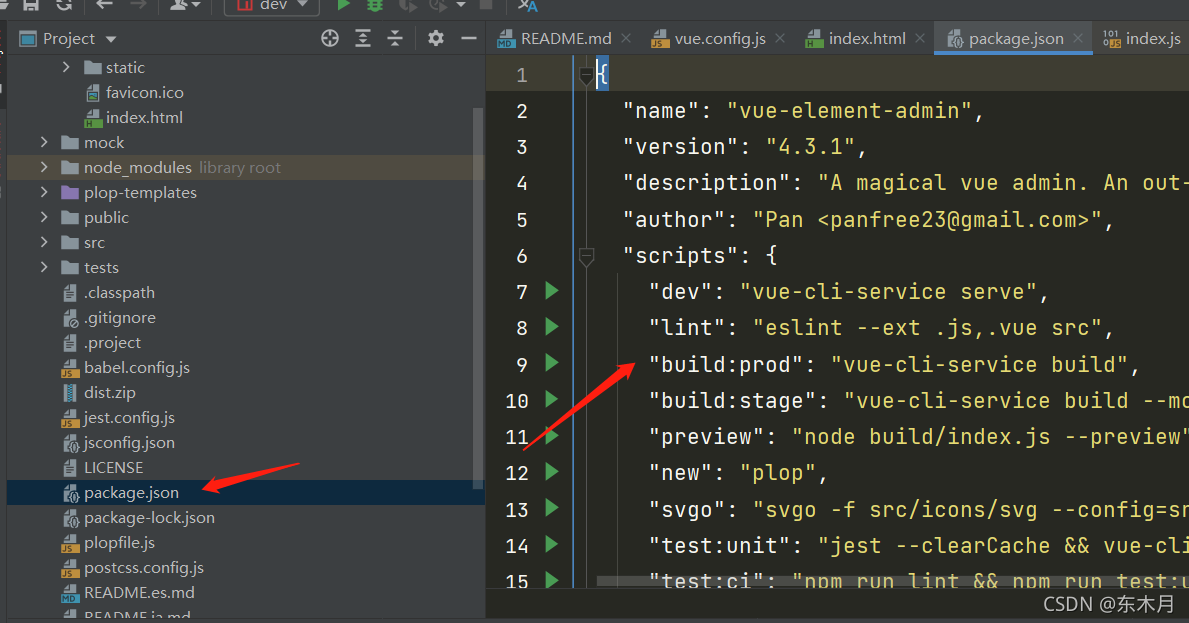
114、vue生成dist文件 安装npm,到官网下载
如果报错,npm ERR! missing script: build,
具体看package.json
115、python获取电脑磁盘、CPU、内存使用情况 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 import psutil # pip install psutil # 获取本机磁盘使用率和剩余空间G信息 def get_disk_info(): # 循环磁盘分区 content = "" for disk in psutil.disk_partitions(): # 读写方式 光盘 or 有效磁盘类型 if 'cdrom' in disk.opts or disk.fstype == '': continue disk_name_arr = disk.device.split(':') disk_name = disk_name_arr[0] disk_info = psutil.disk_usage(disk.device) # 磁盘剩余空间,单位G free_disk_size = disk_info.free//1024//1024//1024 # 当前磁盘使用率和剩余空间G信息 info = "{}盘使用率:{}%%, 剩余空间:{}G ".format(disk_name, str(disk_info.percent), free_disk_size) # 拼接多个磁盘的信息 content = content + info print(content) # cpu信息 def get_cpu_info(): cpu_percent = psutil.cpu_percent(interval=1) cpu_info = "CPU使用率:%i%%" % cpu_percent print(cpu_info) # 内存信息 def get_memory_info(): virtual_memory = psutil.virtual_memory() used_memory = virtual_memory.used/1024/1024/1024 free_memory = virtual_memory.free/1024/1024/1024 memory_percent = virtual_memory.percent memory_info = "内存使用:%0.2fG,使用率%0.1f%%,剩余内存:%0.2fG" % (used_memory, memory_percent, free_memory) print(memory_info) if __name__ == '__main__': get_disk_info() get_cpu_info() get_memory_info()
116、max比较字典列表 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 ''' 使用max函数比较字典列表对象 需求:找出用户组最大id的字典 ''' def com_id(f): ''' 比较用用户ids列表 :param f: 字典 :return: 返回最大的用户id ''' return max(f['user_ids']) friends_added = [ {'user_ids': [1, 2], 'create_at': '2020-01-01'}, {'user_ids': [3, 6], 'create_at': '2020-01-02'}, {'user_ids': [2, 1], 'create_at': '2020-02-02'}, {'user_ids': [4, 1], 'create_at': '2020-02-02'}, ] # max函数中使用key参数,指定自定义函数来比较 item = max(friends_added, key=com_id) item_1 = max(friends_added, key=lambda f: max(f['user_ids'])) # com_id可以转成lambda函数 print(item) print(item_1) 输出: {'user_ids': [3, 6], 'create_at': '2020-01-02'} {'user_ids': [3, 6], 'create_at': '2020-01-02'}
117、django查询表的具体字段 1 2 3 4 5 ExampleModel.objects.values('id', 'username') # 返回的结果是QuerySet, 里面的元素是dict格式 # [{'id':1, 'username': 'Austin'}, {'id':2, 'username':'Sam'}, ...] # 相当于SQL中的SELECT id, username FROM ......, # 只返回对应属性(字段)的值
118、MySQL查询数据添加自增序号 1 2 3 set @i = 0; select waveform, '沿桥风吹' as label ,(@i:=@i+1) xh from alert_message where is_real=1 and node_id=138
119、MySQL 时间截取年月日 1 2 3 4 5 select id, addtime, date_format(addtime,'%Y-%m-%d') as short_time from alert_message where date_format(addtime,'%Y-%m-%d') = '2022-03-13'
120、 列表取奇数下标值 1 2 3 4 5 6 list1=['a' ,'b' ,'c' ,'d' ,'e' ] print ('奇数下标值' ,list1[1 ::2 ])输出: 奇数下标值 ['b' , 'd' ]
121、列表取偶数下标值 1 2 3 list1=['a' ,'b' ,'c' ,'d' ,'e' ] print ('偶数下标值' ,list1[::2 ])偶数下标值 ['a' , 'c' , 'e' ]
122、列表相同元素分类、分组 1 2 3 4 5 6 7 8 9 import itertoolsdata = [1 , 2 , 2 , 2 , 2 , 3 , 3 , 3 , 4 , 4 , 4 , 4 , 1 , 'a' , 'a' ] a =[list (group) for key, group in itertools.groupby(data)] print (a)输出: [[1 ], [2 , 2 , 2 , 2 ], [3 , 3 , 3 ], [4 , 4 , 4 , 4 ], [1 ], ['a' , 'a' ]]
123、ubuntu切换用户 1)从user用户切换到root用户
124、numpy二维数组获取某一列 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import numpy as np a = [ [1, 2, 3, 4, 5, 6], [7, 8, 9, 10, 11, 12], [13.2, 14.8, 15.9, 16.10, 16.11, 17.12], ] a_np = np.array(a) # 把二维列表转成numpy数组 print('第一行', a_np[0].tolist()) # 获取第一行 print('第一列', a_np[:, 0].tolist()) # 获取第一列 输出: 第一行 [1.0, 2.0, 3.0, 4.0, 5.0, 6.0] 第一列 [1.0, 7.0, 13.2]